이전시간에 자연어 데이터를 이용하기 위해 문장을 의미 있는 단위로 구별(토크나이징)하고 구별한 토큰을 컴퓨터가 이해할 수 있는 데이터로 변환(워드 임베딩)을 실시하였다. 그리고 데이터를 직렬로 이어 붙이면 순서에 의미가 없는 데이터가 되므로 병렬로 쌓아 (batch, time steps, sequence length) 형태로 전처리함을 이야기하였다.
as, soon의 문자에 대해 순서대로 ('as', 'as', 'soon'), ('soon', 'as', 'as'), ('as', 'soon', 'as') 이고
as → [1. 0.],
soon → [0. 1.] 일 때 데이터 전처리 결과는
[ [ [1. 0.]
[1. 0.]
[0. 1.] ]
[ [0. 1.]
[1. 0.]
[1. 0.] ]
[ [1. 0.]
[0. 1.]
[1. 0.] ] ]
(3, 3, 2)
잘 살펴보면 흑백 이미지 데이터 (batch, width, height)과 shape이 같음을 확인할 수 있다. 사실 예전에는 언어 데이터를 CNN 기반으로 접근하는 방법론도 있었다고 한다. (참고: Convolutional Neural Networks for Sentence Classification (emnlp2014.org) ) 가볍게 살펴보고 그냥 그렇구나 하고 넘어가도 좋다.
1. 이전값을 부여할 수 있는 신경망
다시 돌아와서, 위의 데이터를 처리할 수 있는 신경망은 어떤 형태여야 할까? 문제를 다시 살펴보자.
"as soon as" → 1
"as as soon" → 0
"soon as as" → 0
목표값이 1이 되기 위해서, 순서는 무조건 as → soon → as 여야 한다.
즉, 순서에 의미를 부여할 수 있는 신경망이 되어야 한다.
이를 수식으로 포현해 보자.

다음값을 결정하는 요소로 현재값과 더불어 이전값을 넣으면 된다.
"as soon as"에 대하여 순서대로 실시해 보면 아래와 같다.
활성화함수를 통과하기 전이라는 뜻으로 ` 표시를 하였음.
신경망에서 사용하는 문자들로 다시 정리하자.
- 이전값과 현재값의 중요도를 결정하는 α, β, b는 '가중치들(Weights)'이다. 일반적으로 아래와 같이 표기한다.
- X', Y', Z', X, Y, Z는 직접 출력되는 값들이 아니기 때문에 은닉값, 또는 은닉 상태로 불리우며 h로 표기한다.
- 순서를 첨자로 h_1, h_2, h_3... 식으로 표현한다.
2. 순환 신경망(Recurrent Neural Network)
보는 바와 같이 이전 출력이 현재 입력의 일부로 들어간다. 이러한 형태의 신경망을 순환 신경망(RNN)이라고 한다.
활성화 함수로 tanh를 사용하는 이유는 relu를 사용하면 출력 > 0인 경우 쉽게 발산하기 때문이다. sigmoid는 너무 기울기가 작기 때문에 이를 절충할 수 있는 tanh를 사용한다.
위 식을 일반화 한다면 다음과 같다.
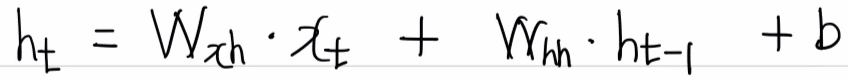
또한 이와 같이 여러 개의 토큰을 입력하여 한 개의 출력으로 해결하는 문제를 many to one 이라고 한다.
문제 접근 방법에 따라 아래와 같이 다양한 방법이 존재한다.
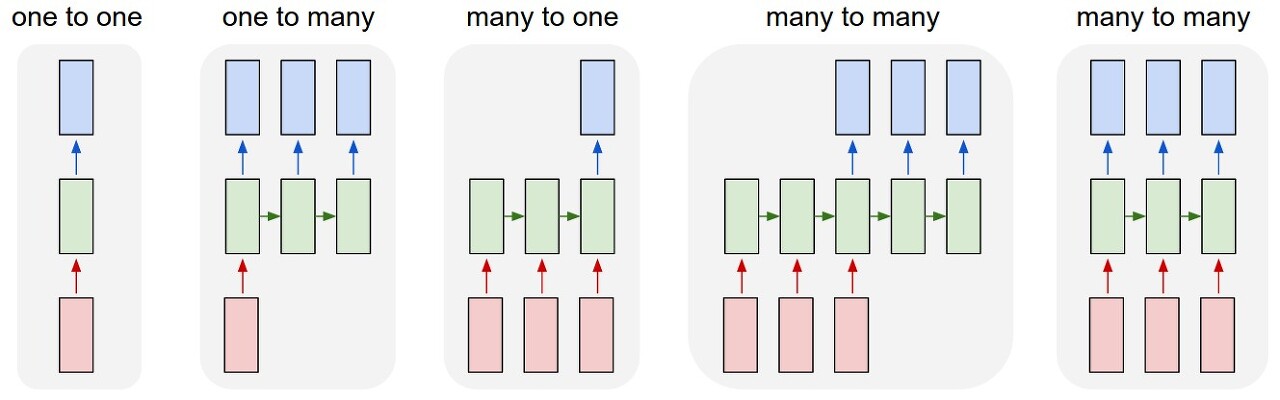
3. 은닉 상태의 가중치 설정하기
원 핫 인코딩 된 한개의 토큰은 현재 [1, 0], [0, 1] 2개의 특성으로 구성되어 있다. 이를 은닉 상태에서 3개로 변경하고 싶을 때 어떻게 하면 될까?
먼저 아래와 같이 용어를 정리하자.
- 은닉상태 노드(Hidden state node) = 3 → h.n(3)
- 단어(토큰) 개수(Sequence length) = 2 → s.l(2)
- 출력 특성(Output feature) = 1 → o.f(1)
은닉상태의 특성 갯수를 결정하는 요소는 은닉상태의 노드이고, 단어(토큰) 개수는 2개(as, soon), 출력은 0 또는 1의 1개의 특성만 가지므로 1이다. 이를 잘 기억하고 은닉 상태의 일반화 식을 다시 접근하자.
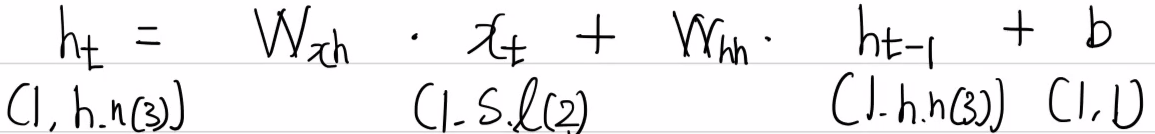
이 때 Wxh와 Whh는 어떤 값이 되어야 할까? 행렬 곱 연산을 자세히 살펴보면 이 상태에서 연산은 힘들다. 조금 변경하여 살펴보면 아래와 같다.
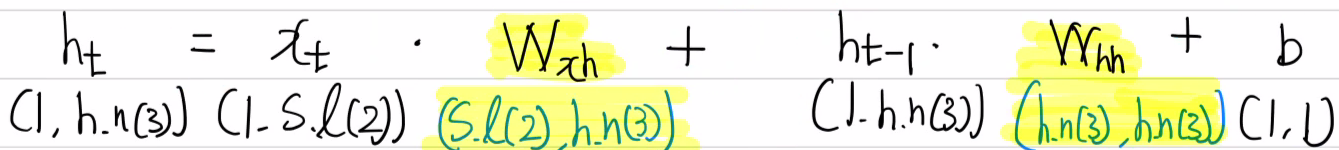
4. 분류기(Fully Connected Layer) 가중치 설정하기
분류기 가중치는 이전시간에 계속 학습했던 방법을 사용하면 된다. 단, 은닉상태의 연산과 통일성을 갖기 위해 W*X(^T)를 사용하지 않고 X*W를 사용해 보겠다.

5. 가중치 최종 정리
RNN의 은닉층에서와 분류기 FC에서 가져야 할 가중치들은 아래와 같다.
- Wxh = ( sequence length(2), hidden node(3) ) → ( 2, 3 )
- Whh = ( hidden node(3), hidden node(3) ) → ( 3, 3 )
- Bh = (1, 1)
- Wy = ( hidden node(3), output feature(1) ) → ( 3, 1 )
- By = (1, 1)
다음 시간에는 이를 코드로 구현하여 순전파를 진행해 보자.
'파이썬 프로그래밍 > Numpy 딥러닝' 카테고리의 다른 글
| 41.[RNN기초] RNN(many to one) 역전파 구현(이론) (0) | 2023.09.19 |
|---|---|
| 40.[RNN기초] RNN(many to one) 순전파 구현(실습) (0) | 2023.09.13 |
| 38.[RNN기초] 자연어 데이터는 어떻게 접근해야 할까? (0) | 2023.09.11 |
| 37. [CNN기초] 다채널(multi channel) 다루기 (0) | 2023.02.18 |
| 36. [CNN기초] 원, 네모를 구별하는 CNN 만들기(실습) (2) | 2023.02.01 |



