일반적으로 CNN은 이미지, 영상등에서 많이 쓰이지만 이번 예제에서 어떤 원리로 훈련하는지 알기 위해 가장 간단한 1차원 배열로 표현해 보자.
문제
입력 [1., 0.7, 0.5, 0.3, 0.1]인 X = (5, ) 배열을
[1, 1, 1,]로 초기화 된 W = (3, ) 필터로 stride = 1인 합성곱을 하고
[0.5]로 초기화 된 B(1, )의 편향을 추가하면
pred = (3, ) 결과가 출력된다.
이때 목표 [1., 0., 0.] Y = (3, )로 pred를 훈련하고 싶다면 어떻게 하면 될까?

1. 문제를 수학으로 표현하기
먼저 연산 과정을 정의하자.
1) 순전파(Forward)
순전파는 입력 Input → 합성곱 Conv(X, W, B) → 합성곱 출력값을 pred로 아래와 같이 정의한다.

2) 오차함수(Loss function)
오차함수는 아래와 같이 간단하게 MSE(Mean Squared Error), 평균제곱오차를 사용한다.
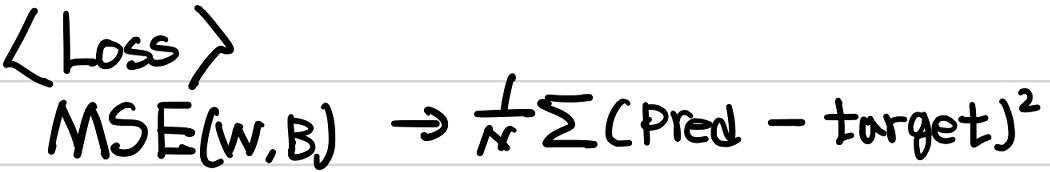
3) 역전파(Backward)
오차에 대한 가중치 W와 편형 B의 기울기는 아래와 같이 구할 수 있다.

2. 1차원 배열 합성곱의 순전파와 역전파
1) 1차원 배열 합성곱의 순전파
아래와 같이 가중치 배열의 요소를 입력 요소와 하나씩 곱해야 하므로 반복문이 필요하다.
이 반복문 변수를 j로 두고자 한다.

이 과정을 코드로 표현하면 아래와 같다.

손으로 한번 계산해 보자. pred 요소를 각각 y_hat으로 표기한다면 y_hat_0은 2.2가 된다.
아직 편향을 구현하지 않았다.

이제 나머지 y_hat_1과 y_hat_2에 대해서 계산한다.
합성곱 결과는 (3, ) 이므로 위 j에 대한 for문 계산을 3번 더 해야 한다. 즉, 이중 for문이 필요하다.
(이것이 합성곱이 어려운 이유...ㅜㅜ)

이 과정을 코드로 표현하면 아래와 같다. y_hat_0을 구현한 코드를 for문으로 한 번 더 감싼 것이다.

손으로 한번 계산해 보자. 마찬가지로 아직 편향을 구현하지는 않았다.
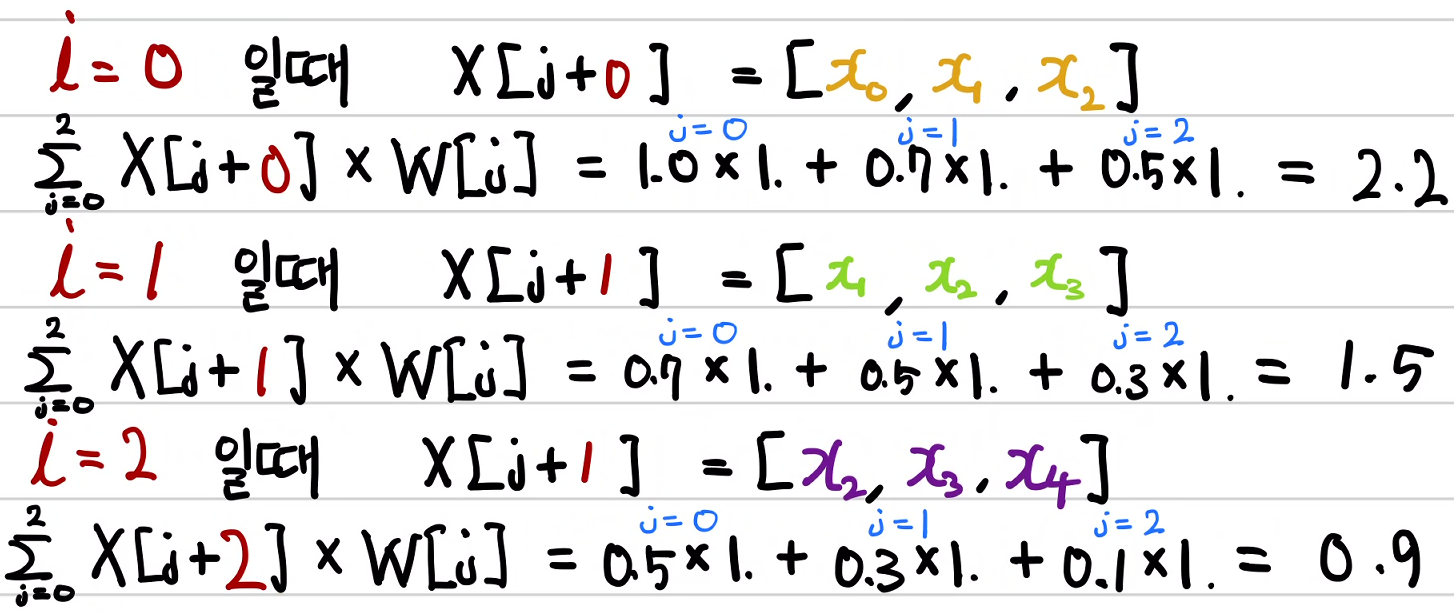
이를 편향까지 고려하여 최종 forward 함수로 정의해 보자.
return conv+ bias에서 (3, )인 pred 각 요소에 편향항인 0.5가 각각 더해짐에 주목하라
그래서 2.2+0.5, 1.5+0.5, 0.9+0.5 가 되어 최종 pred = [2.7, 2.0, 1.4]가 된다.
def forward(input, weight, bias):
conv = np.zeros(3,)
for i in range(3):
a = 0
for j in range(3):
a += input[j+i]*W[j]
conv[i] = a
return conv + bias
print(forward(X, W, B)) # [2.7 2. 1.4]
이를 수식으로 표현하면 아래와 같다.
i는 0부터 합성곱 출력 요소 개수(conv out) 까지
j는 0부터 필터 요소 개수(w.shape) 까지 반복한다.

2) 1차원 배열 합성곱의 역전파
1차원 배열 합성곱의 역전파를 구현해 보자.
conv = X ⓒ W + B로 정의하였을 때 conv에 대한 W의 기울기는 아래와 같다.

W의 기울기를 함수로 구현해 보자. W 요소곱이 사라졌음에 주목하라.
def gradient_conv (input, weight):
grad_conv = np.zeros(3,)
for i in range(3):
a = 0
for j in range(3):
a += X[j+i]
grad_conv[i] = a
return grad_conv
print(gradient_conv(X, W)) # [2.2 1.5 0.9]
conv에 대한 B의 기울기는 아래와 같다.

linear 연산에서 편향항 기울기 구하기와 같다. (모르겠다면 Numpy 딥러닝 정주행~)
따라서 전체 역전파는 아래와 같다.
먼저 오차에 대한 가중치 W의 기울기를 구해보자.
dL_dconv 와 dconv_dW를 요소끼리 곱해주면 된다.

오차에 대한 편향 B의 기울기를 구해보자.
dconv_dB는 요소가 1인 항등원이므로 연산에서 제외하고
dL_dconv 요소들의 합을 진행하면 된다.

3. 코드 구현하기
코드로 하나씩 구현해 보자. 입력 X와 목표값 Y이다. matplolib를 이용해 X를 이미지화 하였다.
가중치 W와 편향 B를 구현한다.

합성곱 연산을 구현한 것이다. y_hat_0을 계산한 결과이다. 아래 손 계산과 비교해 보자.

합성곱 순전파 코드이다. 앞의 코드와 동일하다.
return conv + bias 항을 시행하였으므로
아래 손 계산에서 편향항 0.5를 각각 더해준 것과 같다.

MSE 손실함수의 구현이다. Numpy 정주행 시리즈에서 첫 번째 기초 선형 회귀를 참고해 보자.

합성곱의 역전파 구현이다. 위의 설명과 동일하며
W = [1., 1., 1.]로 초기화 되어있기 때문에
X ⓒ W 와 X의 연산 결과가 역전파 시행 전에는 동일하다.
훈련을 거듭할 수록 달라진다. 어떻게 달라질지 상상해 보자.

역전파를 이용하여 오차에 대한 가중치 W와 편향 B의 기울기 구하기 구현이다.
주석(#) 부분에서 배열 크기가 어떻게 변하는지 주목하자
각 구현 과정은 마찬가지로 Numpy 딥러닝 기초 선형 회귀 부분을 참고하면
더 잘 이해할 수 있다.

|
|
[7. 48, 6, 2.52] 를 [1., 0., 0.] 으로 매칭하도록 훈련해야 한다. 과연 가능할까?
경사하강법으로 가중치를 훈련한다.
epoch가 10의 배수이면 순전파를 하여 출력 결과를 확인해본다.
잘 보면 [1., 0., 0.]에 가까워지고 있음을 알 수 있다.
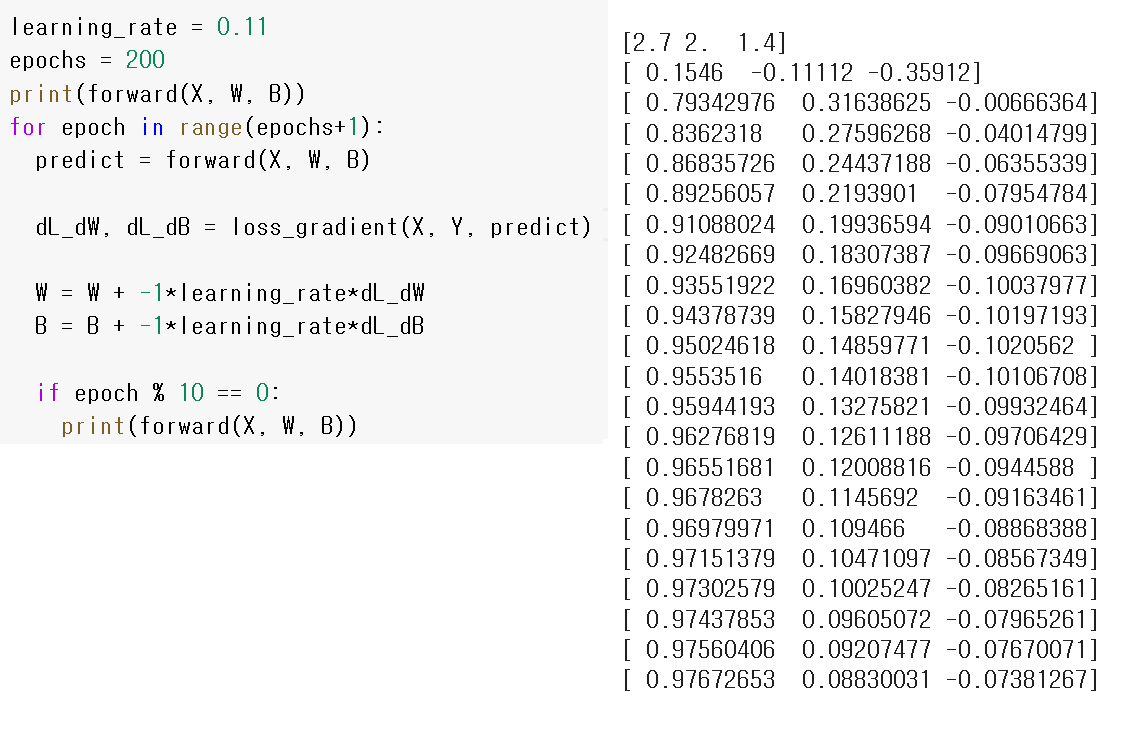
순전파, 가중치, 편향이 어떻게 훈련되었는지 확인해 보자.

아래는 전체 코드이다.
import numpy as np
import matplotlib.pyplot as plt
X = np.array([1., 0.7, 0.5, 0.3, 0.1])
Y = np.array([1., 0., 0.])
W = np.array([1., 1., 1.])
B = np.array([0.5])
def forward(input, weight, bias):
conv = np.zeros(3,)
for i in range(3):
a = 0
for j in range(3):
a += input[j+i]*W[j]
conv[i] = a
return conv + bias
def loss(pred, target):
losses = np.mean(np.power((pred - target), 2))
return losses
def gradient_conv (input, weight):
grad_conv = np.zeros(3,)
for i in range(3):
a = 0
for j in range(3):
a += X[j+i]
grad_conv[i] = a
return grad_conv
def loss_gradient(input, target, pred):
dL_dY = 2*(pred-target) # (3, )
dY_dW = gradient_conv(input, W) # (3, )
dL_dW = dL_dY * dY_dW # (3, ) * (3, ) = (3, ) -> 요소곱
dL_dB = np.sum(dL_dY) # (3, ) → (1, )
return dL_dW, dL_dB
learning_rate = 0.11
epochs = 200
print(forward(X, W, B))
for epoch in range(epochs+1):
predict = forward(X, W, B)
dL_dW, dL_dB = loss_gradient(X, Y, predict)
W = W + -1*learning_rate*dL_dW
B = B + -1*learning_rate*dL_dB
if epoch % 10 == 0:
print(forward(X, W, B))
print(W)
print(B)
'파이썬 프로그래밍 > Numpy 딥러닝' 카테고리의 다른 글
| 29. [CNN기초] 1차원 배열 CNN 훈련하기-3(패딩,선형연산) (1) | 2023.01.05 |
|---|---|
| 28. [CNN기초] 1차원 배열 CNN 훈련하기-2(배치구현) (0) | 2023.01.04 |
| 26. [CNN기초] CNN 개요 (0) | 2023.01.01 |
| 25 - Deep Neural Nets 구현하기 (0) | 2022.04.20 |
| 24. 딥러닝에서 데이터 표준화, 정규화가 필요한 이유 (0) | 2022.04.19 |



