딥러닝에 들어가기 앞서, 데이터 전처리(preprocessing)은 정말 미친듯이 중요하다. 전처리만 잘해도 훈련 성공률은 어마무시하게 올라간다. 전처리에는 일반적으로 통계학(statistics)이 사용된다. 그래서 극단적으로 표현하면 인공지능 = 통계 라고 볼 수 있다. 그렇다면 딥러닝을 위한 전처리는 어떻게 해야 할까 이번시간엔 이에 대한 수학적 개념을 짚고 넘어갈 것이다.
대표값(Representative value) 이라는 개념이 있다. 대표값은 어떤 데이터를 대표하는 하나의 값 이라고 생각하면 되는데 예를들면
· 어떤 학급의 과학 점수 데이터 집단 대표값 : 평균
· 어떤 학급의 모의고사 데이터 집단 대표값 : 총점
· 어떤 학급의 세벳돈 데이터 집단 대표값 : 중앙값
→ 왜냐하면 아예 못 받은 학생, 학생 치고 너무 많이 받은 학생은 제외해야 한다.
· 어떤 학급의 좋아하는 간식 데이터 집단 대표값 : 최빈값
→ 왜냐하면 간식을 주문할 경우 가장 선호도가 많은(최빈값) 음식으로 주문하기 때문
1. 평균(mean)
용어의 정의부터 알아보자. 평균의 의미로 average, mean 두 가지가 쓰이는데 쉽게 이야기하면 average는 mean의 종류 중 하나이다. 평균에는 산술평균, 기하평균, 조화평균 등이 있는데 average는 arthmetic mean 이라고 하여 산술평균이라고 한다. (reference : https://www.cuemath.com/data/difference-between-average-and-mean/ )
이건 너무 쉬우니 패스,
2. 분산(Variance)
데이터들이 평균을 기준으로 얼마나 퍼져 있는가를 나타낸 것이다. 예를 들어 두 학생이 활을 쏘는데
A : 1점, 3점, 5점, 7점, 9점
B : 3점, 4점, 5점, 6점, 7점
평균으로 볼 때 A와 B의 평균은 5점으로 같으나, B의 '편차'가 더 작다. B의 점수가 평균 근처에 더 모여 있다고 볼 수 있다. 만약 9점을 쏠 수 있는 A를 선발한다면 9점이 아닌 1점을 많이 쏜다면 손해가 아니겠는가?
편차(Deviation)는 평균과 데이터 값들의 차이를 의미한다(데이터값 - 평균). 평균이 5점 이므로 편차를 각각 계산하면
A 편차 : -4점, -2점, 0점, 2점, 4점
B 편차 : -2점, -1점, 0점, 1점, 2점
편차를 그대로 활용하기에는 2가지 문제가 있는데
첫 번째로 편차의 크기가 중요한 것이지 양수 음수가 중요한 것이 아니다. 즉, 얼마만큼 떨어져 있는가가 중요하지 -4점이든 4점이든 크기가 '4만큼' 떨어져 있다는 것이 중요하다.
두 번째로 편차의 대표값을 구하기 위해 편차를 다 더해버리면 0이 되어 버릴 수 있다.
이를 해결하기 위해 각 편차 제곱의 평균을 낸다. 이를 분산이라고 한다. 각 분산(σ^2)을 구해보자
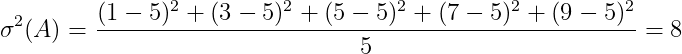

3. 표준편차(Standard Deviation)
위의 분산을 그대로 사용하면 문제가 있는데. 분산은 퍼져 있는 '정도'를 의미하는데 분산의 단위를 보면 (점^2) 의 단위가 된다. 그래서 분산을 제곱근 한 것이 표준편차이다. 위의 각 분산의 표준편차(σ)를 각각 구해보자.

4. 표준편차 사용의 문제점
1) 표준편차는 각 데이터간 떨어진 간격 '크기'를 의미하는 것이 아니다. 평균으로부터 퍼진 '정도'를 의미한다.
2) 같은 척도를 가진 데이터에서 분산, 표준편차의 크기는 의미가 있을 수 있다. 예를 들면 각 학급별 과학점수는 같은 척도를 가지고 반마다 편차가 다를 수 있다. 하지만 다른 데이터 사이에서 분산과 표준편차의 비교는 의미가 없다. 즉, 다른 데이터들 사이에서 표준편차로 데이터들 간의 떨어진 정도를 판단할 수 없다.
대표적으로 단위가 달라지는 경우가 있다. 3점, 4점, 5점, 6점, 7점을 최종 계산 때 0.3점, 0.4점, 0.5점, 0.6점, 0.7점으로 나누기 10을 한다고 할 때 분산과 표준편차는 어떻게 될까? 계산해 보면
분산 : 0.02
표준편차 : 0.141421
의미를 잘 생각해 보자. 3, 4, 5, 6, 7 점수를 0.3, 0.4, 0.5, 0.6, 0.7 로 나누었어도, 우리에게는 동일한 점수 간격이 된다. 왜냐하면 점수 간격 개수로 판단하기 때문이다. 그러나 표준편차로 계산하면 간격이 줄어들었으므로 분산이 작아진다. 즉, 10으로 나누어도 데이터 의미는 분산이 동일해야 하는데 계산하면 분산이 동일하지 않다는 것이다.
5. 데이터들 간의 호환 문제
같은 값이라도 어느 데이터인가에 따라서 다른 의미가 된다. 예를들어 12. 단층 퍼셉트론의 한계-2.선형 회귀식의 한계(https://toyourlight.tistory.com/22) 포스트에서 키와 몸무게 관계 데이터를 가져와 보면

60 이란 데이터를 생각해 보자.
몸무게에서 60은 60kg으로 큰 값에 속한다. 그러나 키에서 60은 0.6m로 작은 값에 속한다. weight에서는 60은 큰 값으로 인식해야 하고, height에서는 60은 작은 값으로 인식해야 한다. 이러한 문제는 데이터를 속단해서 판단하면 안된다는 것을 보여준다.
이 문제를 해결하기 위해 두 가지 방법을 생각해 볼 수 있는데
첫 번째로는 데이터 자체를 정해진 공통 간격 안에 넣기 위해 데이터 간격을 늘리거나 줄이는 방법이고
두 번째로는 데이터 간격 자체는 변화시키지 않고 각 데이터의 척도(cm, kg 등)를 공통 척도로 바꾸는 방법이다.

공통 간격으로 데이터 자체를 늘이거나 줄이는 방법을 정규화(Normalization) 라고 하고
공통 척도로 데이터 자체를 다시 줄세우는 방법을 표준화(Standardization) 라고 한다.
6. 정규화(Normalization)
네이버 사전에서 '정규적' 이라고 검색해 보면 아래와 같다.

정규적은 규범, 규정을 의미하는데 데이터 값들을 공통된 규범, 규정의 간격으로 만든다는 뜻으로 생각해 보자.
대표적으로 쓰이는 방법이 Min-Max 정규화이다. 공식은 아래와 같다.
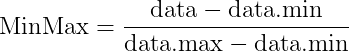
최대 최소로 정규화하는 방법으로 데이터들은 0 ~ 1 사이의 공통 간격으로 재배치된다. 최대값을 1, 최소값을 0으로 만들고 이 사이에서 데이터들을 재배치하는 것이다.
7. 표준화(Standardization)
네이버 사전에서 '표준적' 이라고 검색하면 다음과 같다.

표준적은 근거, 기준을 의미하는데 데이터 값들을 공통된 근거, 기준인 척도를 변경한다고 생각해보자.
대표적으로 쓰이는 방법이 Z score(Z 점수) 이다. 공식은 아래와 같다.
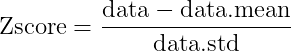
데이터를 데이터의 평균으로 뺀 값을 표준편차(std)로 나누는 것이다. 이렇게 하면 평균0, 표준편차 1인 공통 척도가 만들어진다. 이렇게 하면 데이터 간격의 크기는 달라질 수 있어도 데이터 간격의 의미는 달라지지 않는다. 그래프를 그려보면 데이터의 특징이 그대로 살아있는 것을 볼 수 있다.
8. 결과
위의 내용을 코드로 작성하였을 때 결과는 아래와 같다.
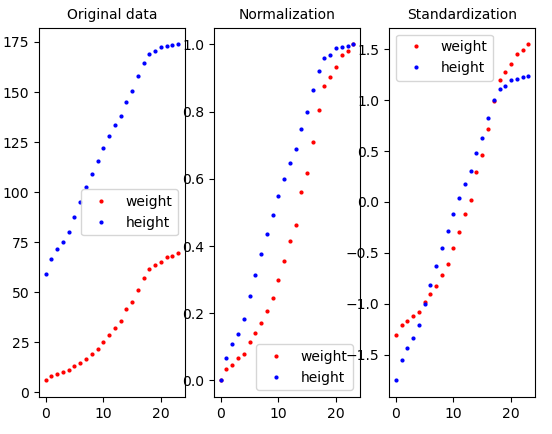
이를 실행하기 위한 코드이다.
import numpy as np
import matplotlib.pyplot as plt
from numpy import genfromtxt
data = genfromtxt('weight_height.csv', delimiter=',', skip_header=1)
weight = data[:, 0]
height = data[:, 1]
fig, ax = plt.subplots(1, 3)
ax[0].plot(weight, 'ro', markersize=2, label='weight')
ax[0].plot(height, 'bo', markersize=2, label='height')
ax[0].set_title('Original data', fontsize=10)
ax[0].legend()
Minmax_weight = (weight-weight.min())/(weight.max() - weight.min())
Minmax_height = (height-height.min())/(height.max() - height.min())
ax[1].plot(Minmax_weight, 'ro', markersize=2, label='weight')
ax[1].plot(Minmax_height, 'bo', markersize=2, label='height')
ax[1].set_title('Normalization', fontsize=10)
ax[1].legend()
Zscore_weight = (weight-weight.mean())/weight.std()
Zscore_height = (height-height.mean())/height.std()
ax[2].plot(Zscore_weight, 'ro', markersize=2, label='weight')
ax[2].plot(Zscore_height, 'bo', markersize=2, label='height')
ax[2].set_title('Standardization', fontsize=10)
ax[2].legend()
print('Zscore_weight mean', Zscore_weight.mean())
print('Zscore_weight std', Zscore_weight.std())
print('Zscore_height mean', Zscore_height.mean())
print('Zscore_height std', Zscore_height.std())
plt.show()
9. 이상치 데이터에 대해
가끔가다 규칙을 벗어나 보이는 이상한 데이터가 들어올 때가 있다. 예를 들어 키는 210cm인데 몸무게는 70kg인 경우라면 어떻게 될까? (https://bodyvisualizer.com/male.html) 사이트에서 미리 볼 수 있는데...

거의 불가능한 키와 몸무게에 가깝지만 지구 어딘가에는 1명쯤 있지 않을까 싶다. 이런 경우 일반적인 키-몸무게 규칙성에 크게 벗어난다. 이 데이터값은 기존 키-몸무게 데이터의 각각 최고값이다. (맨 위의 표를 다시 보세요.)
이 데이터를 기존 데이터에 추가해 보고 표를 다시 그려보자. concatenate를 이용하여 data 최하단에 wrong_data를 추가한다.
data = genfromtxt('weight_height.csv', delimiter=',', skip_header=1)
wrong_data = np.array([[70, 210]])
data = np.concatenate((data, wrong_data), axis=0)

초록색 box가 추가된 worng_data 이고 박스 세로 길이가 차이 간격을 나타낸다.
두 번째 MinMax Normalization에서 차이가 사라졌다. 왜냐하면 wrong_data의 70kg도 weight의 최대값이고 210cm도 height의 최대값이기 때문이다. MinMax Normalization 은 최대값을 1, 최소값을 0으로 둔다는 것에 주목하자. 이러한 성질 때문에 MinMax Normalization은 이상치에 대한 표현이 힘들다.
세 번째 Z score Standardization에서는 original data 만큼은 아니지만 어느 정도 이상치 데이터를 표현한다. 초록색 box의 길이가 어느 정도 남은 것으로 알 수 있다.
그렇다면 Standardization이 최선일까? 꼭 그런것만은 아니다. 이미지 처리 등에서는 Normalization이 더 유용할 수도 있다. 결론적으로 정규화를 하던, 표준화를 하던 훈련이 잘되면 그만이다.
'파이썬 프로그래밍 > 딥러닝과 수학' 카테고리의 다른 글
| 지수가중이동평균(Exponentially Weighted Moving Average)-2 (0) | 2022.01.24 |
|---|---|
| 지수가중이동평균(Exponentially Weighted Moving Average)-1 (2) | 2022.01.24 |
| 7. 2차원 행렬을 입력받는 합성함수의 도함수(실습) (0) | 2021.12.31 |
| 6. 2차원 행렬을 입력받는 합성함수의 도함수(이론) (0) | 2021.12.31 |
| 5. 벡터 합성함수의 도함수 표현 (0) | 2021.12.29 |



