이전 시간까지 주어진 문장이 문법에 맞으면 1, 아니면 0으로 예측하는 RNN 기반 인공신경망을 제작하고 훈련하였다. as soon as로 배치되었을 때 1이고 as as soon, soon as as 이라면 0으로 두었다.
이번엔 가장 간단한 생성형 RNN을 접근해 보자. 바로 many to many 문제이다.

아주 쉽게 접근하는 방법으로 'hello' 문제를 생각해 볼 수 있다. 한글자를 입력하면 그 다음 글자를 예측하는 문제이다.
즉 아래와 같다.
1. h 입력 → e 출력
2. e 입력 → l 출력
3. l 입력 → l 출력
4. l 입력 → o 출력
지금까지 배운 DNN으로 해결할 수 있지 않을까? 생각이 들 수 있는데 나중에 보여주겠지만 잘 되지 않는다. 예를 들어 3번과 4번에서 같은 l이지만 l을 출력 해야 하는 경우와 o를 출력해야 하는 경우가 다르다. 이를 해결하기 위해 그 이전에 어떤 것이 입력 되었는지 정보가 필요하다.
다시 말해 l이 입력 되었을 때 그 전에 e가 입력 되었다면 출력은 l이 되어야 하고, l이 입력될 때 그 이전에 l이 입력되었다면 출력은 o가 되어야 한다. 따라서 DNN은 이 문제를 해결할 수 없다.
이전시간에 진행했던 코드와 상당히 겹치기 때문에 이론과 코드 작성을 동시에 진행하겠다.
1. 전처리
h, e, l, o에 대해 원 핫 인코딩을 실시한다.
import numpy as np
np.random.seed(230912)
dict_hello = {'h':np.array([1, 0, 0, 0]), \
'e':np.array([0, 1, 0, 0]), \
'l':np.array([0, 0, 1, 0]), \
'o':np.array([0, 0, 0, 1]), \
}
print(dict_hello)출력결과
{'h': array([1, 0, 0, 0]), 'e': array([0, 1, 0, 0]), 'l': array([0, 0, 1, 0]), 'o': array([0, 0, 0, 1])}
입력 데이터 input_RNN을 설정한다. 토큰은 h, e, l, o 4개이므로 sequence length는 4, h → e → l → l 순으로 입력되므로 time step은 4이다.
# input 값을 설정
inputs = np.array([])
for text in "hell":
for key, value in dict_hello.items():
if key == text:
if inputs.size == 0:
inputs = np.concatenate([inputs, value])
else:
inputs = np.vstack([inputs, value])
input_RNN = np.reshape(inputs, (1, 4 ,-1 ))
print('inputs shape :', input_RNN.shape)
print(input_RNN)
출력 데이터 targets를 설정한다. 토큰은 h, e, l, o 4개이므로 sequence length는 4, e → l → l → o 순으로 출력되므로 time step은 4이다.
# target 값을 설정
target = np.array([])
for text in "ello":
for key, value in dict_hello.items():
if key == text:
if target.size == 0:
target = np.concatenate([target, value])
else:
target = np.vstack([target, value])
targets = np.reshape(target, (1, 4, -1))
print('target shape :', targets.shape)
print(targets)
2. 변수(Hyper parameters) 설정
- time step 은 4이다. (h → e → l → l 순으로 입력, e → l → l → o 순으로 출력)
- sequence length는 4이다. (h, e, l, o)
- hidden node는 설정하기 나름인데 이전 예제와 같이 3으로 설정하겠다.
- output_feature는 target의 sequence length와 같아야 하므로 4이다.
이를 코드로 작성하면 아래와 같다. 이전 코드와 거의 같다.
time_steps = input_RNN.shape[1] # t.s(4)
sequence_length = input_RNN.shape[2] # s.l(4)
hidden_node = 3 # 내가 설정해야 하는 것, h.n(3)
output_feature = targets.shape[1] # o.f(4)
Wxh = np.random.randn(sequence_length, hidden_node) # (s.l(4), h.n(3))
Whh = np.random.randn(hidden_node, hidden_node) # (h.n(3), h.n(3))
Bh = np.random.randn(1, 1) # (1, 1)
Wy = np.random.randn(hidden_node, output_feature) # (h.n(3), o.f(4))
By = np.random.randn(1, 1) # (1, 1)
3. 순전파 구현
순전파 코드는 이전과 조금 달라지는데 모식도를 살펴보고 어떻게 수정해야 하는지 관찰하자. fc 분류기에서의 활성화 함수는 softmax이다.
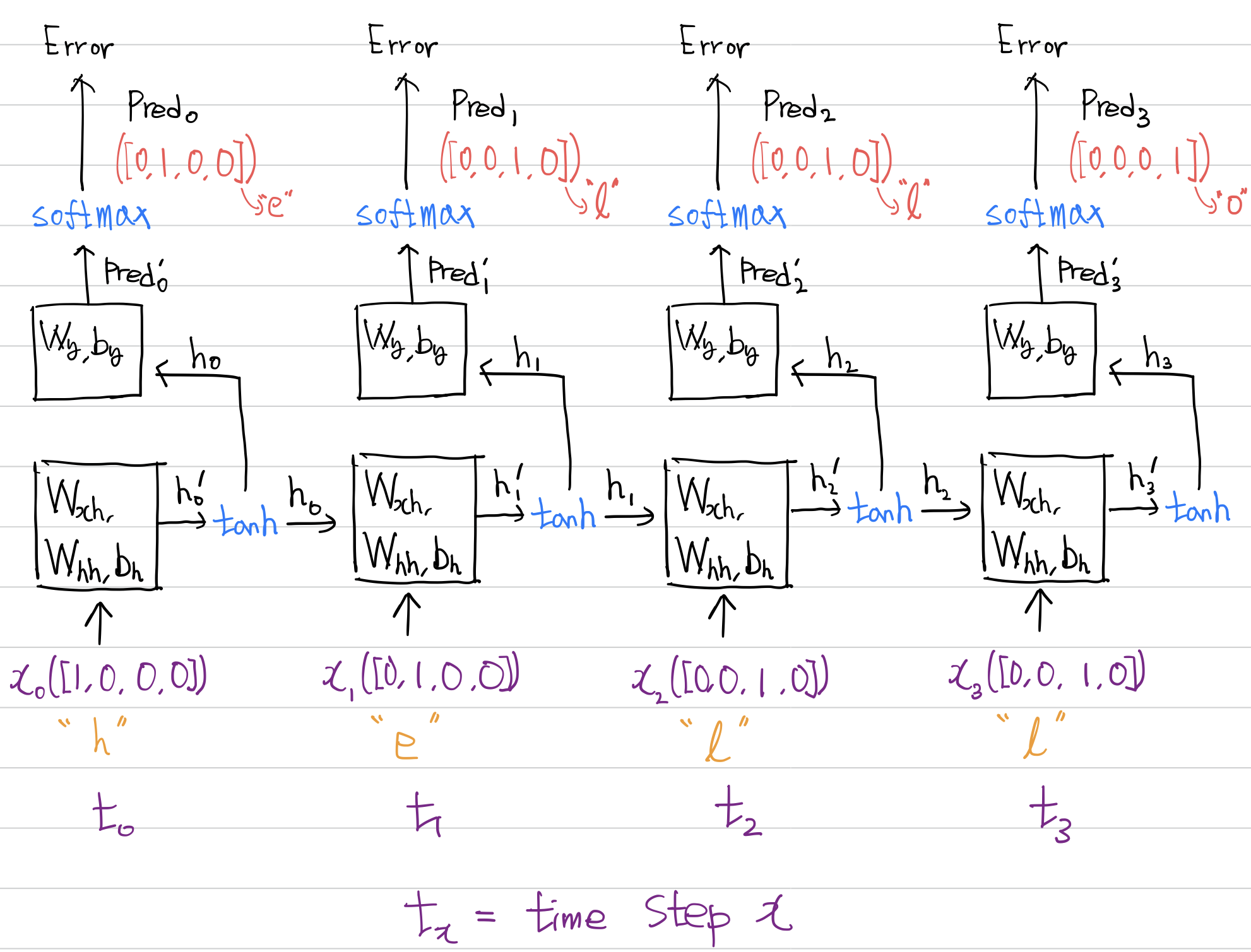
매 순간마다 sequence를 리턴하게 되었으므로 아래와 같은 수정사항이 필요하다.
- many to one에서는 pred`, pred`의 경우 1개만 출력되었으므로 list에 담지 않고 그대로 리턴하였는데 매 순간마다 sequence를 리턴하므로 pred`와 pred을 담을 list가 필요하다.
- for sequence in data 문에서 pred`과 pred 연산은 밖에 있었다. rnn 셀을 time step 만큼 순회한 후 fc 분류기 연산을 해야 하기 때문이다. 그러나 매 순간 sequence를 리턴하므로 pred`와 pred 연산은 for문 안에 있어야 한다.
- fc 분류기에서의 활성화 함수를 softmax로 수정해준다.
이를 코드로 나타내면 아래와 같다.
def rnn_cell(data):
h = np.zeros((1, hidden_node)) #(1, 3) h_-1 상태이며 사실 없으므로 0이다. 반복문을 위해 넣어줌.
# 역전파 계산을 위해 만든 list들
ht_i_list = []
ht_list = []
pred_i_list = [] # many to many에서 필요함.
pred_list = [] # many to many에서 필요함.
ht_list.append(h) # 규칙적인 역전파를 위해 h_-1 상태를 입력함.
count = 0
for sequence in data:
x = np.reshape(sequence, (1, -1))
h_i = np.dot(x, Wxh) + np.dot(h, Whh) + Bh
h = np.tanh(h_i)
pred_i = np.dot(h, Wy) + By # many to many에서 필요함.
pred = np.exp(pred_i)/np.sum(np.exp(pred_i)) # many to many에서 필요함.
ht_i_list.append(h_i)
ht_list.append(h)
pred_i_list.append(pred_i)
pred_list.append(pred)
if count == 0:
total_pred = pred.copy()
else:
total_pred = np.concatenate([total_pred, pred], axis=0)
count = count + 1
return total_pred, pred_list, pred_i_list, ht_list, ht_i_list
predics, pred_list, pred_i_list, ht_list, ht_i_list = rnn_cell(input_RNN[0])
print(predics)
print(pred_list)
print(pred_i_list)
print(ht_list)
print(ht_i_list)
4. 오차 함수 구현
오차함수는 교차 엔트로피 오차(Cross Entropy Error, CEE)이다.
# 오차 계산
def CEE_loss(y_hat, y):
loss = np.sum(-y*np.log(y_hat))
return loss
losses = CEE_loss(predics, targets[0])
print(losses)출력결과
12.062061261168791
다음시간에는 역전파를 구현해 보도록 하겠다.
'파이썬 프로그래밍 > Numpy 딥러닝' 카테고리의 다른 글
| [목차] Numpy 딥러닝 시리즈 (0) | 2023.09.24 |
|---|---|
| 45.[RNN기초] RNN(many to many) 역전파 구현(이론, 실습) (0) | 2023.09.24 |
| 43.[RNN기초] RNN(many to one) 역전파 구현(실습2) (0) | 2023.09.22 |
| 42.[RNN기초] RNN(many to one) 역전파 구현(실습) (0) | 2023.09.20 |
| 41.[RNN기초] RNN(many to one) 역전파 구현(이론) (0) | 2023.09.19 |


