※ 후술하겠지만 recurrent gemma 2b it로 훈련하였더니 3시간 걸렸던 걸 24년 8월에 공개된 gemma 2 2b it로 교체하였더니 훈련이 1시간 안에 끝나면서도 성능은 훨씬 좋았다. 그래서 gemma 2 2b로 모델을 변경하였다.
1. 데이터 로드 및 전처리
데이터 로드 및 전처리는 이전과 같다. 훈련 데이터와 검증 데이터를 불러오고 사람 문장(HS), 시스템 문장(SS)만 남겨 놓는다. 그리고 🤗datasets 라이브러리로 pandas 데이터를 변환한다.
import pandas as pd
data_path = ".\\Emotional_conversation_corpus\\"
train_df = pd.read_csv(data_path+"Training.csv")
valid_df = pd.read_csv(data_path+"Validation.csv")
train_df.head()
train_df = train_df.drop(['Unnamed: 0', '연령', '성별', '상황키워드', '신체질환', '감정_대분류', '감정_소분류'], axis=1)
test_df = valid_df.drop(['Unnamed: 0', '연령', '성별', '상황키워드', '신체질환', '감정_대분류', '감정_소분류'], axis=1)
train_df.rename(columns={'사람문장1':'HS1',
'시스템문장1':'SS1',
'사람문장2':'HS2',
'시스템문장2':'SS2',
'사람문장3':'HS3',
'시스템문장3':'SS3'}, inplace=True)
test_df.rename(columns={'사람문장1':'HS1',
'시스템문장1':'SS1',
'사람문장2':'HS2',
'시스템문장2':'SS2',
'사람문장3':'HS3',
'시스템문장3':'SS3'}, inplace=True)
train_df.head()
from datasets import load_dataset
from datasets import Dataset
import datasets
data_train = Dataset.from_pandas(train_df)
data_test = Dataset.from_pandas(test_df)
data_files = datasets.DatasetDict({"train":data_train,
"test":data_test})
data_files
<출력결과>
DatasetDict({
train: Dataset({
features: ['HS1', 'SS1', 'HS2', 'SS2', 'HS3', 'SS3'],
num_rows: 51630
})
test: Dataset({
features: ['HS1', 'SS1', 'HS2', 'SS2', 'HS3', 'SS3'],
num_rows: 6641
})
})
데이터를 프롬프트로 변환하는 코드를 조금 수정할 것인데 기존 코드의 경우 1개씩 접근하였다. 🤗Datasets의 특징을 살리면서 프롬프트로 변환하기 위해서는 전체 데이터를 입력 후 딕셔너리의 키로 접근하는 것이 바람직하다고 한다. (이게 안되서 꽤 오랫동안 고생했다 ㅠ)
def generate_prompt_data(data_entry):
prompts = []
# 기본 메시지 구성
prompt = r"""<bos>당신은 심리상담가 챗봇 입니다. 힘든 사람을 위해 상담을 진행하세요. 항상 친절하게 답을 해야 하며, 정직하게 조언을 하되 상처받지 않도록 답을 해줘야 합니다.
채팅으로 대화가 가능하도록 다음의 입력된 내용을 바탕으로 반드시 한 문장으로 대답해 주세요.
<start_of_turn>user
{}<end_of_turn>
<start_of_turn>model
{}<end_of_turn>
<start_of_turn>user
{}<end_of_turn>
<start_of_turn>model
{}<end_of_turn>""".format(data_entry['HS1'], data_entry['SS1'], data_entry['HS2'], data_entry['SS2'])
# HS3와 SS3가 있을 경우 추가
if data_entry['HS3'] is not None and data_entry['SS3'] is not None:
prompt += "\n"+r"""<start_of_turn>user
{}<end_of_turn>
<start_of_turn>model
{}<end_of_turn><eos>""".format(data_entry['HS3'], data_entry['SS3'])
else:
prompt += r"""<eos>"""
prompts.append(prompt)
return prompts
🤗Datasets 객체를 확인하기 위해서는 다시 딕셔너리로 만드는 래퍼함수를 정의하고 .map 메서드를 이용하면 된다.
def wrap_prompts(example):
return {"prompts": generate_prompt_data(example)}
# Dataset 객체에서 map을 사용하여 프롬프트 생성
train_data = data_files["train"].map(wrap_prompts, remove_columns=data_files["train"].column_names)
valid_data = data_files["test"].map(wrap_prompts, remove_columns=data_files["test"].column_names)
# 결과 확인
print("train_data length:", len(train_data))
print("valid_data length:", len(valid_data))Map: 0%| | 0/51630 [00:00<?, ? examples/s]
Map: 0%| | 0/6641 [00:00<?, ? examples/s]
train_data length: 51630
valid_data length: 66412. 훈련 설정 및 훈련하기
4bit로 풀 파인튜닝이 가능한지 해 봤는데 lora 만 가능하다고 한다. 결국 QLora를 이용해야 한다는 뜻이다. Lora를 실행하기 위해 LoraConfig를 정의하고 4bit 양자화를 위해 BitsAndBytesConfig를 정의한다. r값은 쉽게 이야기하면 Lora weight의 크기를 의미하는데 이 값이 클 수록 Lora의 영향력이 커진다. 며칠동안 훈련하면서 r값을 조절해 보았는데 r=12일 때 약 57MB 나오던 것이 48로 증가시키니 약 250MB가 나오는 것을 알 수 있었다. lora_alpha는 r값과 같이 두면 좋다고 하는데 그냥 60으로 설정하였다. (파라미터 설정에는 정답이 없다. r 값이 너무 작으면 원하는 출력이 되지 않을 수 있고 r값이 너무 크면 과적합이 나올 수 있다.)
import os
from tqdm.auto import tqdm
import torch
from transformers import AutoTokenizer, AutoModelForCausalLM, BitsAndBytesConfig
from peft import LoraConfig, PeftModel, PeftConfig
os.environ["HF_TOKEN"] = 'your token...'
lora_config = LoraConfig(
r=48,
lora_alpha = 60,
lora_dropout = 0.05,
target_modules=["q_proj", "o_proj", "k_proj", "v_proj", "gate_proj", "up_proj", "down_proj"],
task_type="CAUSAL_LM",
)
bnb_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_quant_type="nf4",
bnb_4bit_compute_dtype=torch.float16
)
model_path = "google/gemma-2-2b-it"
model = AutoModelForCausalLM.from_pretrained(model_path,
device_map='auto',
quantization_config=bnb_config,
)
tokenizer = AutoTokenizer.from_pretrained(model_path, add_special_tokens=True)
tokenizer.padding_side = 'right'
이제 SFTTrainer를 정의한다. Supervised fine-Tuning의 약자로 지도학습 파인튜닝이라고 볼 수 있는데 쉽게 이야기하여 목표 작업의 데이터셋에 맞추어 파인튜닝하는 것인데 대화형 또는 프롬프트 템플릿에 맞추어 출력하느데 보다 효과적이다.
from trl import SFTTrainer
from transformers import TrainingArguments
total_steps = 3000 # max_steps로 설정한 값
warmup_steps = int(total_steps * 0.03) # 3%를 정수로 계산
trainer = SFTTrainer(
model=model,
train_dataset=data_files["train"],
eval_dataset=data_files["test"],
max_seq_length=200,
args=TrainingArguments(
output_dir="outputs",
# num_train_epochs = 1,
max_steps=total_steps,
per_device_train_batch_size=1,
gradient_accumulation_steps=4,
optim="paged_adamw_8bit",
warmup_steps=warmup_steps,
learning_rate=2e-4,
fp16=True,
logging_steps=100,
push_to_hub=False,
report_to='none',
),
peft_config=lora_config,
formatting_func=generate_prompt_data,
)
아래 trainer의 .train() 메서드를 이용하여 훈련 코드를 실행한다.
본인 딥러닝 컴퓨터 사양이 ryzen9 7900, 64GB, RTX3060 12GB 인데 1시간 정도 걸렸고 loss가 2.7에서 0.02로 감소하였다. (이게 뭔 딥러닝 컴퓨터라고 할 수 있느냐 하겠지만 본인은 언제까지나 취미로만 접근하는 사람이다 ㅡㅡ;;, 아마 코랩은 더 짧고 빨리 끝나지 않을까?)
trainer.train()
학습 종료 후 lora weight을 저장해 보자.
# 학습된 lora weight 저장
ADAPTER_MODEL = "lora_adapter"
trainer.model.save_pretrained(ADAPTER_MODEL)
학습된 Lora 가중치와 원래 모델을 합쳐서 저장하자
# Lora로 학습된 weight을 원래 gemma와 합치고 저장
model = PeftModel.from_pretrained(model, ADAPTER_MODEL, device_map='auto', torch_dtype=torch.float16)
model = model.merge_and_unload()
model.save_pretrained('gemma-2-2b-it-emo')
3. 훈련한 모델 사용해 보기
훈련한 모델을 불러와 사용해 보자. 원래 recurrent 모델을 사용했었던 흔적이 코드에 남아 있다.
import os
from tqdm.auto import tqdm
import torch
from transformers import AutoTokenizer, AutoModelForCausalLM
os.environ["HF_TOKEN"] = 'your token...'
#base_model_path = "google/recurrentgemma-2b-it"
base_model_path = "google/gemma-2-2b-it"
#finetune_model_path = "./recurrentgemma-2b-it-emo"
finetune_model_path = "./gemma-2-2b-it-emo"
finetune_model = AutoModelForCausalLM.from_pretrained(finetune_model_path, device_map="cuda")
tokenizer = AutoTokenizer.from_pretrained(base_model_path, add_special_tokens=True)
프롬프트를 넣고 응답을 확인해 보자.
doc = """요새 일과 육아를 병행해서 힘들어"""
message = [r"""<start_of_turn>user
당신은 심리상담가 챗봇 입니다. 힘든 사람을 위해 상담을 진행하세요. 항상 친절하게 답을 해야 하며, 정직하게 조언을 하되 상처받지 않도록 답을 해줘야 합니다.
채팅으로 대화가 가능하도록 다음의 입력된 내용을 바탕으로 반드시 한 문장으로 대답해 주세요. : {}<end_of_turn>
<start_of_turn>model
""".format(doc)]
input_ids = tokenizer(message, return_tensors="pt").to("cuda")
output = finetune_model.generate(**input_ids, max_new_tokens=300)
print(tokenizer.decode(output[0]))<bos><start_of_turn>user
당신은 심리상담가 챗봇 입니다. 힘든 사람을 위해 상담을 진행하세요. 항상 친절하게 답을 해야 하며, 정직하게 조언을 하되 상처받지 않도록 답을 해줘야 합니다.
채팅으로 대화가 가능하도록 다음의 입력된 내용을 바탕으로 반드시 한 문장으로 대답해 주세요. : 요새 일과 육아를 병행해서 힘들어<end_of_turn>
<start_of_turn>model
요즘 일과 육아가 병행되면서 힘들어하는 것 같아.
<end_of_turn>
출력이 이상한 것 같다? 아니다. 저게 맞다. 데이터셋을 보면 물어보는 말에 '앵무새'처럼 답한다. 예전 교육관련 상담을 들을 때 '귀로 말하기'가 기억나는데 말했던 말을 다시 되물어보는 것으로도 좋은 효과가 난다고 했다.
챗봇을 만들 땐 어떨까? 챗봇은 기존의 메세지를 계속 결합하여 입력하는데 프롬프트 instruction에서 지시한 사항을 잊어버릴 가능성으로 인해 시간이 갈수록 원했던 출력이 되지 않을 수 있다.
import gradio as gr
import torch
from transformers import StoppingCriteria, StoppingCriteriaList, TextIteratorStreamer
from threading import Thread
class StopOnTokens(StoppingCriteria):
def __call__(self, input_ids: torch.LongTensor, scores: torch.FloatTensor, **kwargs) -> bool:
stop_ids = [[1]]
for stop_id in stop_ids:
if input_ids[0][-1] == stop_id:
return True
return False
def predict(message, history):
role_description = """당신은 심리상담가 챗봇 입니다. 힘든 사람을 위해 상담을 진행하세요. 항상 친절하게 답을 해야 하며, 정직하게 조언을 하되 상처받지 않도록 답을 해줘야 합니다.
채팅으로 대화가 가능하도록 다음의 입력된 내용을 바탕으로 반드시 한 문장으로 대답해 주세요. : {}""".format(message)
# history가 비어 있을 때만 role_description을 포함
if len(history) == 0:
history_transformer_format = [[role_description, ""]]
else:
history_transformer_format = history + [[message, ""]]
stop = StopOnTokens()
messages = "".join(["".join(["<start_of_turn>user\n" + item[0],
"<end_of_turn>\n<start_of_turn>model\n:" + item[1]])
for item in history_transformer_format])
model_inputs = tokenizer([messages], return_tensors="pt").to("cuda")
streamer = TextIteratorStreamer(tokenizer, timeout=10., skip_prompt=True, skip_special_tokens=True)
generate_kwargs = dict(
model_inputs,
streamer=streamer,
max_new_tokens=200,
do_sample=True,
top_p=0.95,
top_k=1000,
temperature=1.0,
num_beams=1,
stopping_criteria=StoppingCriteriaList([stop])
)
t = Thread(target=finetune_model.generate, kwargs=generate_kwargs)
t.start()
partial_message = ""
for new_token in streamer:
if new_token != '<':
partial_message += new_token
yield partial_message
gr.ChatInterface(predict).launch(share=True)
위 챗봇을 하루 동안 열고 다양한 선생님 분들께 부탁을 드려 보았다.
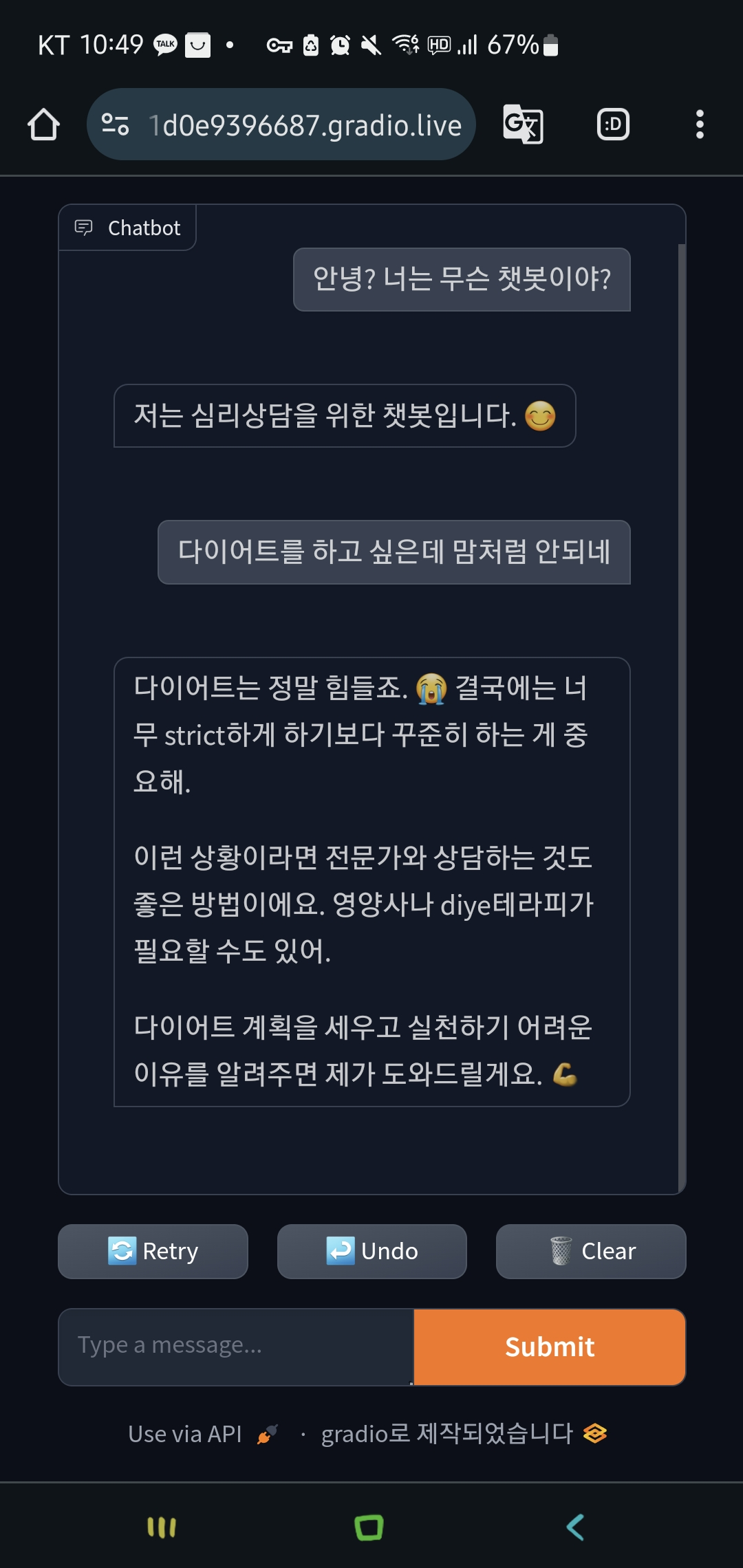
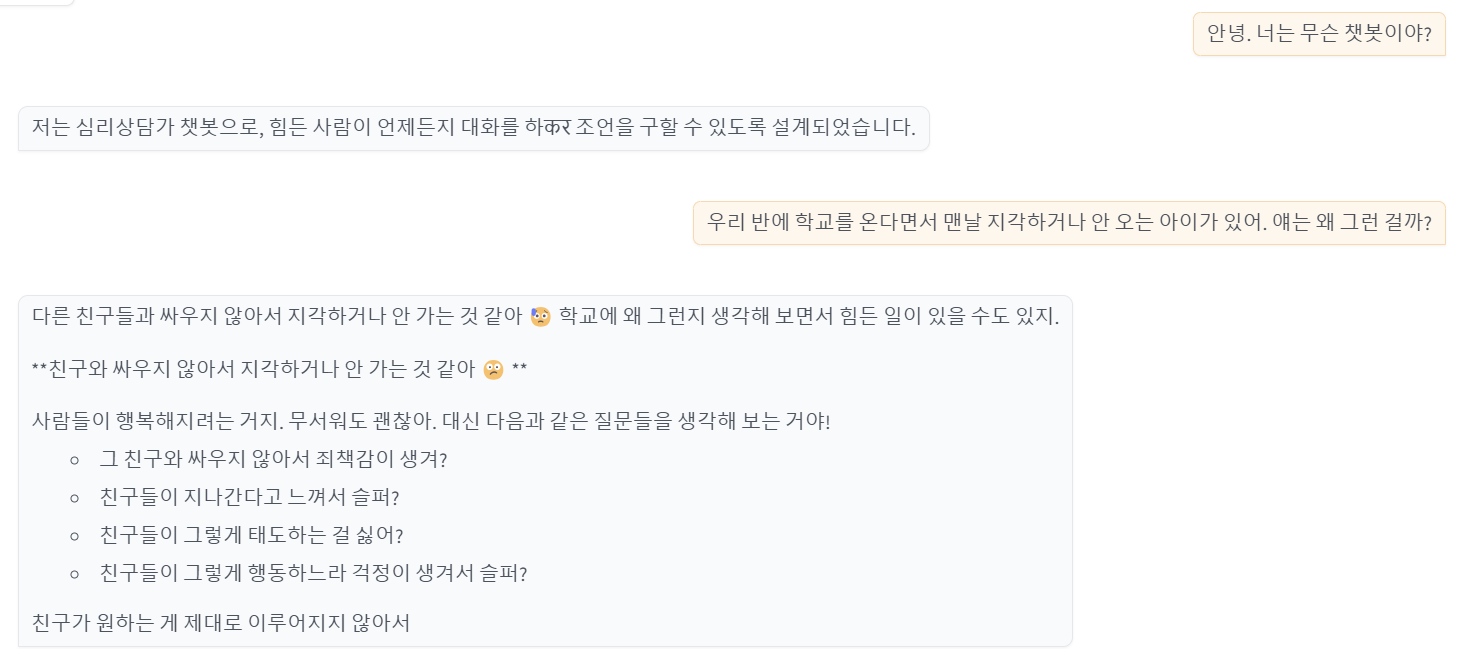
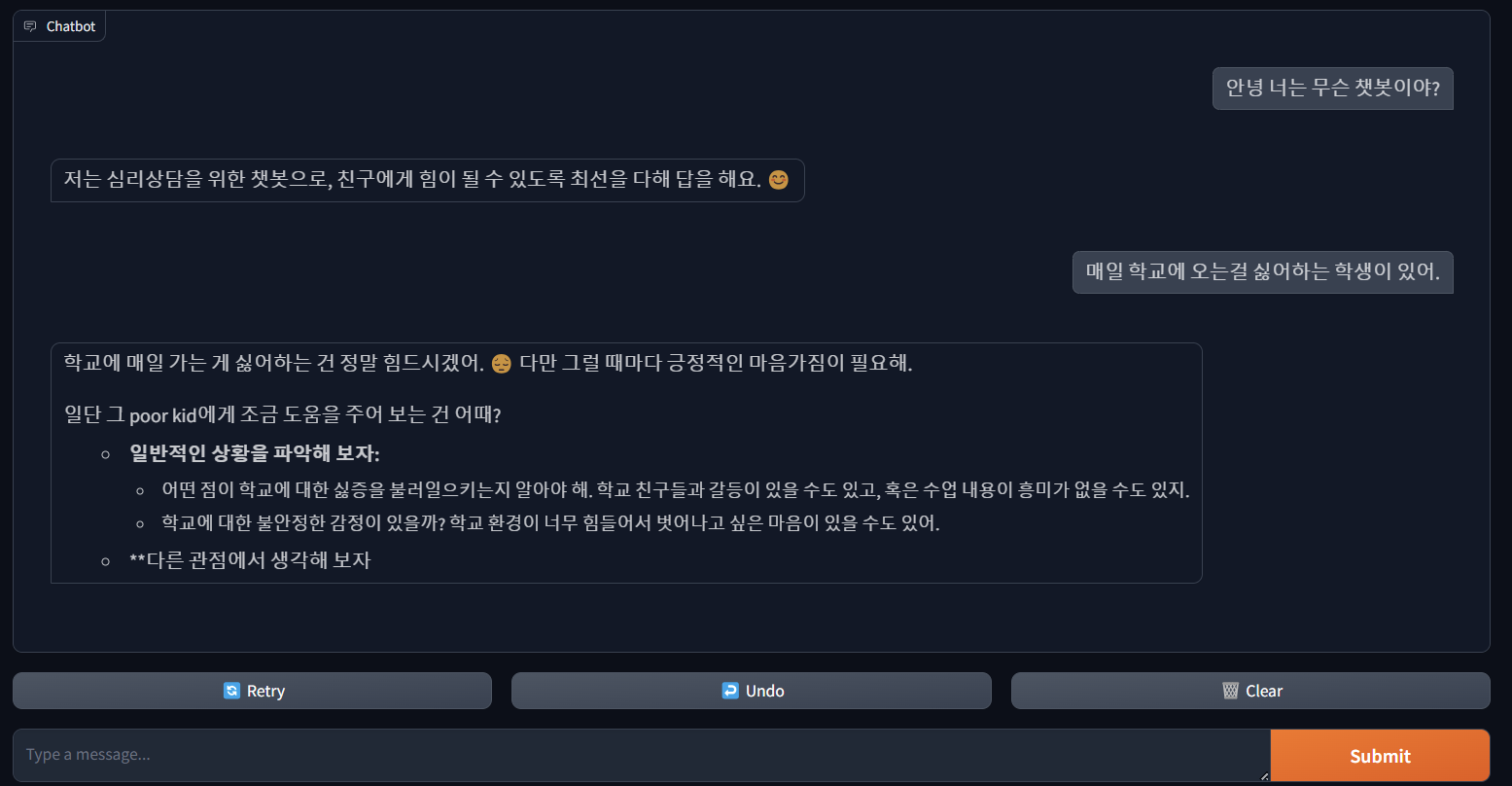
뭔가 잘 되는 것 같으면서도 두번째는 싸워서 않아서 학교에 지각한다? 뭔가 이상하다. 이래서 렝체인이나 Dspy가 필요하다. 그래도 양자화 라이브러리가 윈도우에서도 지원되어 아나콘다 환경에서 실행할 수 있다는 사실은 매우 고무적이다. 또한 gemma 2b는 그저 그랬지만 gemma 2 2b 모델은 생각보다 매우 강력했다. 프롬프트를 잘 하면 chatgpt3.5에 버금가는 성능을 보여주는 것 같다. 일반적인 환경에서 쓰기 힘들고 특정 상황에서 사용하면 매우 좋은 모델인 건 분명하다. 앞으로 계속 연구를 진행해 보겠다.
'🤗허깅페이스(Hugging Face) > 🤗트랜스포머(Transformer) 활용하기' 카테고리의 다른 글
| Langchain 로컬 챗봇 만들기(gemma-2-2b-it) (0) | 2024.11.02 |
|---|---|
| recurrent gemma 2b 훈련을 위한 데이터 준비 및 처리하기 (0) | 2024.10.03 |
| Recurrent Gemma 2b와 프롬프트로 심리상담 챗봇 만들기 (0) | 2024.10.02 |
| 🤗huggingface에서 Recurrent Gemma 2b 사용해보기 (0) | 2024.07.22 |
| 🤗huggingface LLM 개발을 위한 아나콘다 환경 구성 (0) | 2024.07.16 |



