이전시간에 gemma 2b의 태생적 한계로 인해 프롬프트만으로 심리 상담 챗봇을 만들기에 부족함을 알았다. 파인튜닝을 위해 데이터를 준비하고 토큰화할 수 있도록 처리해야 한다. 🤗Huggingface의 🤗datasets 라이브러리를 이용해보자.
1. 데이터 구하기
AI Hub의 '감성 대화 말뭉치'를 이용하였다. 용량도 20MB 정도로 그리 크지 않고 본인 컴퓨터에서 큰 무리 없이 돌릴만 하다고 판단되어 선택하게 되었다.
이 데이터를 이요하려면 회원가입 하고 몇 가지 동의 후 다운받을 수 있다.
데이터 찾기 - AI 데이터찾기 - AI-Hub (aihub.or.kr)
AI-Hub
샘플 데이터 ? ※샘플데이터는 데이터의 이해를 돕기 위해 별도로 가공하여 제공하는 정보로써 원본 데이터와 차이가 있을 수 있으며, 데이터에 따라서 민감한 정보는 일부 마스킹(*) 처리가 되
www.aihub.or.kr
2. 데이터 로드 및 전처리
아래와 같이 판다스로 읽어보자.
import pandas as pd
data_path = ".\\Emotional_conversation_corpus\\"
train_df = pd.read_csv(data_path+"Training.csv")
valid_df = pd.read_csv(data_path+"Validation.csv")
train_df.head()
이 데이터셋은 원래 BERT의 감정 분류로 많이 이용하였다. BERT구조는 MASKING이나 분류에 적합하다. 이번 프로젝트에서는 문장 생성이므로 사람문장(Humen sentence, HS)과 시스템문장(System sentence, SS)만 이용하겠다. 문장이 2번째로만 끝나는 경우 3번째의 사람 문장과 시스템 문장은 없다.
.drop 메서드를 이용하여 나머지를 지워버리자.
train_df.columns
train_df = train_df.drop(['Unnamed: 0', '연령', '성별', '상황키워드', '신체질환', '감정_대분류', '감정_소분류'], axis=1)
test_df = valid_df.drop(['Unnamed: 0', '연령', '성별', '상황키워드', '신체질환', '감정_대분류', '감정_소분류'], axis=1)
train_df.head()
열 이름도 영어로 바꾸자
train_df.rename(columns={'사람문장1':'HS1',
'시스템문장1':'SS1',
'사람문장2':'HS2',
'시스템문장2':'SS2',
'사람문장3':'HS3',
'시스템문장3':'SS3'}, inplace=True)
test_df.rename(columns={'사람문장1':'HS1',
'시스템문장1':'SS1',
'사람문장2':'HS2',
'시스템문장2':'SS2',
'사람문장3':'HS3',
'시스템문장3':'SS3'}, inplace=True)
train_df.head()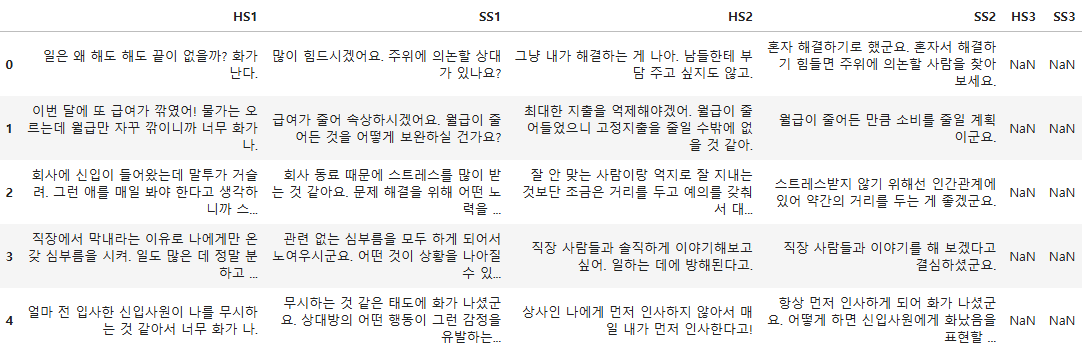
3. 🤗Dataset 라이브러리로 불러오기
Dataset 라이브러리는 데이터세트에 쉽게 엑세스하고 처리하기 위한 라이브러리이다. 딥 러닝 모델에서 훈련할 수 있도록 데이터 세트를 빠르게 준비하며 Apache Arrow 형식을 기반으로 메모리 제약 없이 대규모 데이터 세트를 처리하여 최적의 속도와 효율성을 제공한다... 라고 합니다. .from_pandas 메서드를 이용하여 데이터를 Dataset 객체로 불러오자.
from datasets import load_dataset
from datasets import Dataset
data_train = Dataset.from_pandas(train_df)
data_test = Dataset.from_pandas(test_df)
data_train
이 두개를 하나의 훈련 데이터와 테스트 데이터를 하나의 데이터셋으로 만들어보자.
import datasets
data_files = datasets.DatasetDict({"train":data_train,
"test":data_test})
data_files
제대로 변환이 되었는지 확인해 보자.
data_files["train"][2]
data_files["train"][304]
이제 아래와 같이 프롬프트를 직접 작업해 보자
message = [r"""<bos><start_of_turn>user
당신은 심리상담가 챗봇 입니다. 힘든 사람을 위해 상담을 진행하세요. 항상 친절하게 답을 해야 하며, 정직하게 조언을 하되 상처받지 않도록 답을 해줘야 합니다.
채팅으로 대화가 가능하도록 다음의 입력된 내용을 바탕으로 반드시 한 문장으로 대답해 주세요. : {}<end_of_turn>
<start_of_turn>model
{}<end_of_turn>
<start_of_turn>user
{}<end_of_turn>
<start_of_turn>model
<end_of_turn>""".format(data_files["train"][2]['HS1'], data_files["train"][2]['SS1'], data_files["train"][2]['HS2'])]
print(message)
4. 데이터를 프롬프트로 변환하기
모든 데이터에 대해 프롬프트 변환 작업을 해야 한다. 위의 message를 함수로 만들면 되는데 주의할 점으로 HS3, SS3가 있는 경우가 있고 없는 경우가 있으므로 구별해서 작업하면 된다.
def create_prompt(data_entry):
# 기본 메시지 구성
prompt = r"""<bos><start_of_turn>user
당신은 심리상담가 챗봇 입니다. 힘든 사람을 위해 상담을 진행하세요. 항상 친절하게 답을 해야 하며, 정직하게 조언을 하되 상처받지 않도록 답을 해줘야 합니다.
채팅으로 대화가 가능하도록 다음의 입력된 내용을 바탕으로 반드시 한 문장으로 대답해 주세요. : {}<end_of_turn>
<start_of_turn>model
{}<end_of_turn>
<start_of_turn>user
{}<end_of_turn>
<start_of_turn>model
{}<end_of_turn>""".format(data_entry['HS1'], data_entry['SS1'], data_entry['HS2'], data_entry['SS2'])
# HS3와 SS3가 있을 경우 추가
if data_entry['HS3'] is not None and data_entry['SS3'] is not None:
prompt += "\n"+r"""<start_of_turn>user
{}<end_of_turn>
<start_of_turn>model
{}<end_of_turn><eos>""".format(data_entry['HS3'], data_entry['SS3'])
else:
prompt += r"""<eos>"""
return prompt
# 사용 예시
data_entry_2 = data_files["train"][2]
data_entry_304 = data_files["train"][304]
# 프롬프트 생성
prompt_2 = create_prompt(data_entry_2)
prompt_304 = create_prompt(data_entry_304)
# 결과 출력
print(prompt_2, "\n")
print(prompt_304)
이제 모든 데이터에 대하여 변환해 보자.
def generate_prompt_data(examples):
prompt_list = []
for example in examples:
prompt = create_prompt(example)
prompt_list.append(prompt)
return prompt_list
train_data = generate_prompt_data(data_files["train"])
print(len(train_data))51630
잘 변환되었는지 확인해 보자
print(train_data[2], "\n")
print(train_data[304])
잘 보면 파이썬 List에 프롬프트로 변환한 데이터를 넣는 것을 알 수 있다. 왜 이렇게 했냐고 하니... Tokenizer 입력 형식이 아래와 같이 str, List[str], List[List[str]] 이기 때문이다. 항상 Docs를 잘 확인해야 한다.

test 데이터도 똑같이 처리하면 된다.
다음시간엔 4bit로 양자화 한 다음 Lora 없이 full fine tuning을 진행하겠다.
'🤗허깅페이스(Hugging Face) > 🤗트랜스포머(Transformer) 활용하기' 카테고리의 다른 글
| Langchain 로컬 챗봇 만들기(gemma-2-2b-it) (0) | 2024.11.02 |
|---|---|
| gemma-2-2b-it 파인튜닝하기 (0) | 2024.10.11 |
| Recurrent Gemma 2b와 프롬프트로 심리상담 챗봇 만들기 (0) | 2024.10.02 |
| 🤗huggingface에서 Recurrent Gemma 2b 사용해보기 (0) | 2024.07.22 |
| 🤗huggingface LLM 개발을 위한 아나콘다 환경 구성 (0) | 2024.07.16 |



