4. 추론 전략 탐색
LLM은 데이터의 패턴 인식에는 뛰어나지만, 복잡한 다단계 문제에 필요한 상징적 추론에 어려움을 보이기도 한다. 신경망 패턴 완성과 의도적인 상징적 조작을 결합한 고급 추론 전략을 구현해 볼 수 있다.
- 사실들의 체인에서 결론을 도출하기 위한 다단계 연역 추론
- 방정식을 변형의 연속을 통해 풀어내는 수학적 추론
- 문제를 최적의 일련의 동작으로 분해하기 위한 계획 전술
명시적인 추론 단계와 함께 도구를 통합함으로써 에이전트는 추상화와 상상력이 필요한 문제에 대처할 수 있으며 복잡한 세계에 대한 복잡한 이해를 얻어 더 의미 있는 대화를 나눌 수 있다.
관찰 종속적 추론(observation-dependent reasoning)에서 에이전트는 LLM에게 생각과 동작을 생성하기 위해 반복적으로 맥락과 예제를 제공한다. 도구로부터의 관찰은 다음 추론 단계를 알리기 위해 통합된다 → Action 에이전트에서 사용
계획 및 실행(Plan-and-execute)에서 PlannerLLM은 계획 목록(P)를 생성한다. 에이전트는 도구를 사용해 증거(E)를 수집한다. P와 E는 결합되 Solver LLM에 공급돼 최종 출력을 생성한다.
Plan-and-execute는 계획과 실행을 분리한다. Planner 및 Solver 역할에는 더 작은 전문화된 모델을 사용할 수 있다. 이 때의 트레이드오프는 Plan-and-execute가 더 많은 초기 계획을 필요로 한다.
플래너(LLM)은 계획 및 도구 사용에 대한 세부 조정이 가능하며, 계획 목록(P)을 생성하고 워커(agent)를 호출에 도구를 사용해 증거(E)를 수집한다. P와 E는 작업과 결합돼 솔버(LLM)으로 전달돼 최종 답변을 생성한다.
- 모든 단계를 계획한다.(플래너)
- 각 단계에 대해 적절한 도구를 결정하고 실행한다.
<툴-강화 LLM 패러다임>
<aside> 💡 Planner
<context promt> For the folloing tasks, ...
<Exemplars> For example ... What is the name of the cognac house that makes the main ingredient in The Hennchata?
Plan: Search for more information about The Hennchata.
#E1 = Wikipedia[The Henchata]
Plan: Find out the main ingredient of The Hennchata.
#E2 = LLM[What is the main ingredient of The Hennchata? Given context: # E1]
Plan: Search for more information about the main ingredient.
#E3 = Wikipedia[#E2]
Plan: find out the cognac house that makes the main ingredient.
#E4 = LLM[What is the name of the cognac house that makes the main ingredient #E2? Given context: # E3]
플래너
<context promt> 다음 작업에 대해...
<예시자> 예를 들면...
헨차타에서 주재료를 만드는 꼬냑 집 이름은?
플랜: 헨차타에 대한 더 많은 정보를 검색합니다.
#E1 = 위키백과 [헨차타]
계획: 헨차타의 주성분을 알아보세요.
#E2 = LLM [헨차타의 주성분은? 주어진 맥락: #E1]
계획: 주성분에 대한 더 많은 정보를 검색합니다.
#E3 = 위키백과[#E2]
계획: 주재료를 만드는 꼬냑 집을 알아봅니다.
#E4 = LLM[주재료 #E2를 만드는 꼬냑집 이름은? 주어진 맥락 : #E3]
</aside>
→ to Worker, Solver
<aside> 💡 Worker
#E1 = Wikipedia[The Hennchata]
Evidence: The Hennchata is a cocktail consisting of Hennessy cognac...
#E2 = LLM[What is the main ingredient of The Hennchata? Given context: The Hennchata is a cocktail consisting of Hennessy cognac...]
Evidences: Hennessy cognac
#E3 = Wikipedia[Hennessy cognac]
Evidence: Jas Hennessy & Co., commonly known...
#E4 = LLM[What is the name of the cognac house that makes the main ingredient Hennessy cognac? Given Context: Jas Hennessy & Co., commonly known...]
Evidence: Jas Hennessy & Co.
작업자
#E1 = 위키백과[헨차타]
증거: 헤넨차타는 헤네시 코냑으로 구성된 칵테일입니다...
#E2 = LLM [더 헨차타의 주성분은? 주어진 맥락: 더 헨차타는 헤네시 코냑으로 구성된 칵테일...]
증거: 헤네시 코냑
#E3 = 위키백과[헤네시 코냑]
증거: 자스 헤네시, 일반적으로 알려진...
#E4 = LLM [주재료 헤네시 코냑을 만드는 코냑집 이름은? 주어진 맥락: 자스 헤네시앤코, 흔히 알려진...]
증거 : Jas Hennessy & Co.
</aside>
→ To Solver
<aside> 💡 Solver
<Context prompt> Solve the task given provided plans and evidence...
Plan: Search for more information about The Hennchata.
Evidence: The Hennchata is a cocktail consisting of Hennessy cognac and Mexican rice horchata agua fresca ...
Plan: Find out the main ingredient of The Hennchata.
Evidence: Hennessy cognac
Plan: Search for more information about the main ingredient.
Evidence: Jas Hennessy & Co., commonly known simply as Hennessy (French pronunciation: [enesi])..
Plan: Find out the cognac house that makes the main ingredient.
Evidence: Jas Hennessy & Co.
Answer: Jas Hennessy & Co.
솔버
<Context prompt> 제공된 계획과 증거가 제시된 과제 해결...
플랜: 헨차타에 대한 더 많은 정보를 검색합니다.
증거: 헤넨차타는 헤네시 코냑과 멕시코 쌀 호르차타 아구아 프레스카로 구성된 칵테일입니다...
계획: 헨차타의 주성분을 알아보세요.
증거: 헤네시 코냑
계획: 주성분에 대한 더 많은 정보를 검색합니다.
증거: 흔히 헤네시(프랑스어 발음: [enesi])로 알려진 Jas Hennessy & Co..
계획: 주재료를 만드는 꼬냑 집을 알아봅니다.
증거 : Jas Hennessy & Co.
답변 : Jas Hennessy & Co.
</aside>
# <Utils.py>
"""Utility functions and classes."""
from langchain.memory import ConversationBufferMemory
from langchain.prompts import MessagesPlaceholder
def init_memory():
"""Initialize the memory for contextual conversation.
We are caching this, so it won't be deleted
every time, we restart the server.
"""
return ConversationBufferMemory(
memory_key='chat_history',
return_messages=True,
output_key='answer'
)
MEMORY = init_memory()
CHAT_HISTORY = MessagesPlaceholder(variable_name="chat_history")
- from langchain.memory import ConversationBufferMemory 대화 내용을 버퍼에 저장하고 관리하는 기능을 제공한다.
- from langchain.prompts import MessagesPlaceholder 대화 내용을 저장하고 불러오는 데 사용된다.
- **ConversationBufferMemory(memory_key='chat_history', return_messages=True, output_key='answer')** ConversationBufferMemory 객체를 생성하여 반환한다. memory_key='chat_history': 대화 내용을 'chat_history'라는 키로 저장한다. return_messages=True: 대화 내용을 메시지 형태로 반환한다. output_key='answer': 대화 응답을 'answer'라는 키로 반환한다.
- **CHAT_HISTORY = MessagesPlaceholder(variable_name="chat_history")** MessagesPlaceholder 객체를 생성하고, CHAT_HISTORY 변수에 저장한다. 이 객체는 대화 내용을 저장하고 불러오는 데 사용된다.
- 이렇게 LangChain의 메모리 기능을 활용하여 대화 내용을 저장하고 관리할 수 있다. 이를 통해 사용자와의 대화를 지속적으로 유지하고, 이전 대화 내용을 참조할 수 있으며. API 사용 비용을 절감할 수 있다.
# <agent.py>
from typing import Literal
from langchain.agents import initialize_agent, load_tools, AgentType
from langchain.chains.base import Chain
from langchain_experimental.plan_and_execute import (
load_chat_planner, load_agent_executor, PlanAndExecute
)
#from config import set_environment
#set_environment()
ReasoningStrategies = Literal["zero-shot-react", "plan-and-solve"]
def load_agent(
llm,
tool_names: list[str],
strategy: ReasoningStrategies = "zero-shot-react"
) -> Chain:
tools = load_tools(
tool_names=tool_names,
llm=llm
)
if strategy == "plan-and-solve":
planner = load_chat_planner(llm)
executor = load_agent_executor(llm, tools, verbose=True)
return PlanAndExecute(planner=planner, executor=executor, verbose=True)
return initialize_agent(
tools=tools,
llm=llm,
agent=AgentType.ZERO_SHOT_REACT_DESCRIPTION,
verbose=True,
handle_parsing_errors = True
)
코드는 에이전트를 로드하는 기능을 정의하며, 주어진 전략에 따라 적절한 에이전트 타입(계획 및 실행 또는 제로샷 반응)을 초기화하여 반환한다.
- from typing import Literal: Literal 타입을 임포트하여 특정 값들만을 가질 수 있는 변수의 타입을 지정할 수 있게 한다.
- from langchain.chains.base import Chain: langchain 라이브러리의 기본 체인 클래스를 임포트한다.
- from langchain_experimental.plan_and_execute import (load_chat_planner, load_agent_executor, PlanAndExecute): langchain_experimental 모듈에서 챗 플래너와 에이전트 실행자를 로드하는 함수와 계획 및 실행 클래스를 임포트한다.
- ReasoningStrategies = Literal["zero-shot-react", "plan-and-solve"]: 추론 전략을 "zero-shot-react"와 "plan-and-solve" 두 가지 리터럴 값 중 하나로 제한하는 타입을 정의한다.
- def load_agent(llm, tool_names: list[str], strategy: ReasoningStrategies = "zero-shot-react") -> Chain:: 에이전트를 로드하는 함수를 정의한다. 이 함수는 LLM, 도구 이름 목록, 그리고 전략을 입력으로 받고 Chain 객체를 반환하다.
- if strategy == "plan-and-solve":: 전략이 "plan-and-solve"인 경우 해당 블록의 코드를 실행한다. planner = load_chat_planner(llm): 챗 플래너를 로드한다. executor = load_agent_executor(llm, tools, verbose=True): 에이전트 실행자를 로드하며, 상세한 로그 출력을 활성화한다. return PlanAndExecute(planner=planner, executor=executor, verbose=True): PlanAndExecute 객체를 생성하여 반환한다. 이 때, 상세한 로그 출력이 활성화된다.
- return initialize_agent(tools=tools, llm=llm, agent=AgentType.ZERO_SHOT_REACT_DESCRIPTION, verbose=True, handle_parsing_errors = True): 전략이 "plan-and-solve"가 아닌 경우, initialize_agent 함수를 호출하여 에이전트를 초기화하고 반환한다. 여기서도 상세한 로그 출력이 활성화되며, 파싱 오류를 처리하는 옵션이 활성화된다.
# <app.py>
"""Question answering app in Streamlit.
Originally based on this template:
<https://github.com/hwchase17/langchain-streamlit-template/blob/master/main.py>
Run locally as follows:
> PYTHONPATH=. streamlit run question_answering/app.py
Alternatively, you can deploy this on the Streamlit Community Cloud
or on Hugging Face Spaces. For Streamlit Community Cloud do this:
1. Create a GitHub repo
2. Go to Streamlit Community Cloud, click on "New app" and select the new repo
3. Click "Deploy!"
"""
import streamlit as st
from streamlit.external.langchain import StreamlitCallbackHandler
from agent import load_agent
from utils import MEMORY
from langchain_community.llms import LlamaCpp
model_path = "D:\\gpt4all\\Download model\\Meta-Llama-3-8B-Instruct.Q4_0.gguf"
n_batch = 512 # Should be between 1 and n_ctx, consider the amount of VRAM in your GPU.
n_ctx = 8192 # llama.context_length = 8192, 0 = from model
temperature = 0.75
top_p = 0.95
llm = LlamaCpp(
model_path=model_path,
temperature = temperature,
top_p = top_p,
n_batch=n_batch,
n_ctx = n_ctx,
stream = True,
f16_kv=True,
verbose=True, # Verbose is required to pass to the callback manager
)
st.set_page_config(page_title="LangChain Question Answering", page_icon=":robot:")
st.header("Ask a research question!")
strategy = st.radio(
"Reasoning strategy",
("plan-and-solve", "zero-shot-react", ))
tool_names = st.multiselect(
'Which tools do you want to use?',
[
"google-search", "ddg-search", "wolfram-alpha", "arxiv",
"wikipedia", "python_repl", "pal-math",
"llm-math"
],
["ddg-search", "wolfram-alpha", "wikipedia"])
if st.sidebar.button("Clear message history"):
MEMORY.chat_memory.clear()
avatars = {"human": "user", "ai": "assistant"}
for msg in MEMORY.chat_memory.messages:
st.chat_message(avatars[msg.type]).write(msg.content)
assert strategy is not None
agent_chain = load_agent(llm=llm, tool_names=tool_names, strategy=strategy)
assistant = st.chat_message("assistant")
if prompt := st.chat_input(placeholder="Ask me anything!"):
st.chat_message("user").write(prompt)
with st.chat_message("assistant"):
st_callback = StreamlitCallbackHandler(st.container())
response = agent_chain.invoke(
{"input": prompt}, {"callbacks": [st_callback]}
)
st.write(response["output"])Streamlit을 사용하여 LangChain 기반의 질의응답 시스템을 구현하는 코드이다.
- from streamlit.external.langchain import StreamlitCallbackHandler: Streamlit과 LangChain을 연동하기 위한 CallbackHandler를 가져온다.
- from agent import load_agent: 이전에 정의한 load_agent 함수를 가져온다. 이 함수는 LangChain 에이전트를 초기화하는 데 사용됩니다.
- from utils import MEMORY: 대화 기록을 관리하기 위한 MEMORY 객체를 가져온다.
- st.set_page_config(page_title="LangChain Question Answering", page_icon=":robot:"): 페이지의 제목과 아이콘을 설정한다.
- st.header("Ask a research question!"): 페이지 상단에 헤더를 추가한다.
- strategy = st.radio(...): 사용자가 추론 전략을 선택할 수 있는 라디오 버튼을 생성한다.
- tool_names = st.multiselect(...): 사용자가 사용할 도구들을 다중 선택할 수 있는 선택 상자를 생성한다.
- if st.sidebar.button("Clear message history"):: 사이드바에 '메시지 기록 지우기' 버튼을 추가하고, 이 버튼이 클릭되면 조건문 내의 코드가 실행된다. MEMORY.chat_memory.clear(): 대화 기록을 지우는 코드이다.
- avatars = {"human": "user", "ai": "assistant"}: 메시지 유형에 따라 사용할 아바타를 설정하는 딕셔너리이다.
- for msg in MEMORY.chat_memory.messages:: 저장된 대화 메시지를 순회하는 반복문이다. st.chat_message(avatars[msg.type]).write(msg.content): 각 메시지를 적절한 아바타와 함께 채팅 창에 출력한다.
- assert strategy is not None: strategy 변수가 None이 아님을 확인하는 코드이다.
- agent_chain = load_agent(llm=llm, tool_names=tool_names, strategy=strategy): 선택된 LLM, 도구, 전략을 사용하여 에이전트를 로드한다.
- assistant = st.chat_message("assistant"): 'assistant' 아바타로 채팅 메시지를 초기화하지만, 이후 사용되지 않는다.
- if prompt := st.chat_input(placeholder="Ask me anything!"):: 사용자로부터 입력을 받는 필드를 생성한다. 입력이 있으면 prompt 변수에 저장된다. st.chat_message("user").write(prompt): 사용자 아바타로 사용자의 질문을 채팅 창에 출력합니다. with st.chat_message("assistant"):: 'assistant' 아바타를 사용하여 채팅 메시지 블록을 시작한다. st_callback = StreamlitCallbackHandler(st.container()): Streamlit 콜백 핸들러를 초기화한다. response = agent_chain.invoke(...): 에이전트 체인을 호출하여 사용자의 질문에 대한 응답을 생성합니다. st.write(response["output"]: 사용자의 질문에 대한 에이전트의 응답을 스트림릿 페이지에 출력합니다.
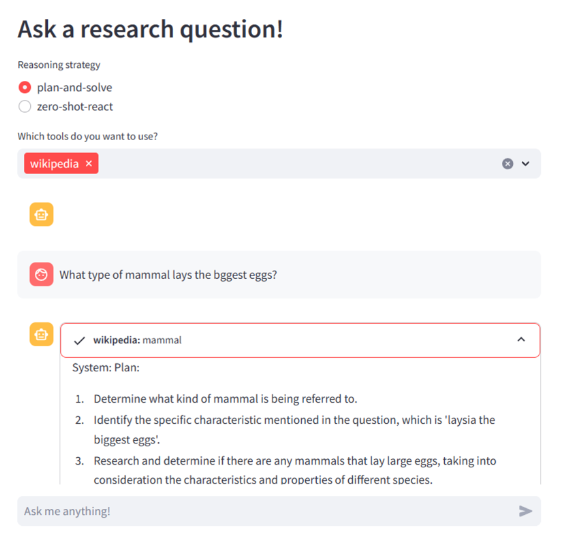
나름 잘 된다! 신기하다 ㅎㅎ
'📚도서 공부 > LangChain으로 구현하는 LLM' 카테고리의 다른 글
| 5-2(챗봇이란?, 벡터 저장소) 챗봇 만들기 (0) | 2024.05.09 |
|---|---|
| 5-1(챗봇이란?, 임베딩) 챗봇 만들기 (0) | 2024.05.02 |
| 4-3-2(시각 인터페이스 구축) Langchain 비서 구축 (0) | 2024.04.25 |
| 3. LangChain 시작해보기(Windows, llama cpp python) (0) | 2024.04.24 |
| 4-3-1(툴을 사용한 질문 응답) Langchain 비서 구축 (0) | 2024.04.23 |

