Streamlit을 이용할 것이다.
아래는 streamlit 기초 튜토리얼 자료이다. 주피터노트북 파일이 아닌 파이썬 파일(.py)로 실행해야 하기 때문에 myapp.py로 작성하였다.
import streamlit as st
st.title("Streamlit Test")
st.write("hello world")
st.write("""
# MarkDown
> comment
- one
- two
- three
""")이 상태에서 Anaconda Powershell Prompt에 실행하면 주피터노트북과 포트가 겹치는 것으로 보인다. 따라서 포트를 다른 것으로 바꿔 줘야 한다.

streamlit run E:\Tuning_LLM\myapp.py --server.port 30001
출력 결과!
챗봇을 만들어 보자.
from langchain_community.llms import LlamaCpp
from langchain_core.callbacks import CallbackManager, StreamingStdOutCallbackHandler
from langchain.agents import AgentExecutor, AgentType, initialize_agent, load_tools
import streamlit as st
from langchain.callbacks import StreamlitCallbackHandler
model_path = "E:\\GPT4ALL\\Download Models\\Meta-Llama-3-8B-Instruct.Q4_0.gguf"
n_gpu_layers = -1 # 32, The number of layers to put on the GPU. The rest will be on the CPU. If you don't know how many layers there are, you can use -1 to move all to GPU.
n_batch = 512 # Should be between 1 and n_ctx, consider the amount of VRAM in your GPU.
n_ctx = 8192 # llama.context_length = 8192, 0 = from model
temperature = 0.75
top_p = 0.95
callback_manager = CallbackManager([StreamingStdOutCallbackHandler()])
llm = LlamaCpp(
model_path=model_path,
temperature = temperature,
top_p = top_p,
n_gpu_layers=n_gpu_layers,
n_batch=n_batch,
n_ctx = n_ctx,
stream = True,
f16_kv=True,
callback_manager=callback_manager,
verbose=True, # Verbose is required to pass to the callback manager
)
def load_agent(llm) -> AgentExecutor:
# DuckDuckGoSearchRun, wolfram alpha, arxiv search, wikipedia
# TODO: try wolfram-alpha!
tools = load_tools(
tool_names=["wikipedia", "arxiv"],
llm=llm
)
return initialize_agent(
tools=tools, llm=llm, agent=AgentType.ZERO_SHOT_REACT_DESCRIPTION, verbose=True)
chain = load_agent(llm)
st_callback = StreamlitCallbackHandler(st.container())
if prompt := st.chat_input():
st.chat_message("user").write(prompt)
with st.chat_message("assistant"):
st_callback = StreamlitCallbackHandler(st.container())
response = chain.run(prompt, callbacks=[st_callback])
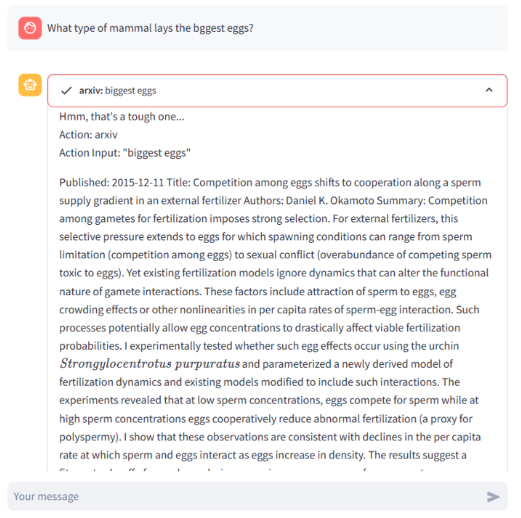
st.write(response)음… 뭔가 터진 것 같긴 해요… 그래도 GPT4All 보단 잘되네!
handle_parsing_errors=True to the AgentExecutor 옵션을 하라는데
더 공부하고 찾아봐야 겠음.
'📚도서 공부 > LangChain으로 구현하는 LLM' 카테고리의 다른 글
| 5-1(챗봇이란?, 임베딩) 챗봇 만들기 (0) | 2024.05.02 |
|---|---|
| 4-4(추론 전략 탐색) Langchain 비서 구축 (0) | 2024.04.27 |
| 3. LangChain 시작해보기(Windows, llama cpp python) (0) | 2024.04.24 |
| 4-3-1(툴을 사용한 질문 응답) Langchain 비서 구축 (0) | 2024.04.23 |
| 4-2-3(정보요약, 맵 리듀스 파이프라인) Langchain 비서 구축 (0) | 2024.04.22 |

