저번시간에 가위바위보 문제를 Q learning(Q 학습)으로 해결해 본다고 하였습니다. 가장 먼저 가위바위보가 이루어지는 환경(Environment)을 정의해야 합니다.
1. 환경(Environment)
가. 상태(State)
가위바위보는 상대편의 가위, 바위, 보를 예측하여 이기기 위해 세가지 중 하나를 선택하는 게임입니다. 인공지능은 환경의 상태 (State) 를 관찰합니다. 여기서 환경의 상태는 '상대편의 가위, 바위, 보'로 정의해 볼 수 있습니다. 인공지능 입장에서 플레이어가 상대이니까 상대의 가위, 바위, 보 중 어떤 것을 내었는지가 환경의 상태가 되겠습니다.

나. 행동(Action)
인공지능은 상태를 관찰하고 현재 상태에 대한 최적의 행동(Action)을 하기 위해 Q함수에게 현재 상태에서 행동에 따른 기대 보상(Q값)을 물어봅니다. 즉, Q함수는 어떤 행동을 하였을 때 다음 상태(Next state)에서의 기대 보상인 Q값을 알려줍니다. 인공지능은 Q값이 가장 큰 행동을 취합니다.
주의할점으로, 현재 상태에 대해 이기는 것이 아닙니다. 인공지능은 플레이어의 다음 상태에 대하여 Q값으로 예측하고 행동하는 것입니다.
이를 사람으로 치환하면, 상대 플레이어는 현재 '바위'상태이지만, 다음에는 '보'를 낼 것이므로 나는 '가위'를 내겠다. 로 생각해 볼 수 있습니다.

다. 다음 상태(Next state)
인공지능이 행동을 취하면 다음 상태가 됩니다. 다음상태는 플레이어가 '가위', '바위', '보' 중 하나를 낸 것입니다. 예를 들어 '보'를 냈다고 가정해 보겠습니다.

라. 보상(reward)
인공지능은 행동에 대하여 다음 상태에 대한 보상을 받습니다. 이긴다면 +1점, 비기거나 지면 -1점을 주도록 하겠습니다. 인공지능이 플레이어를 이겼으므로 +1점을 줍니다.

2. Q함수 정의하기
Q함수를 보면 어떤 상태 s에서 행동 a를 하였을 때 기대값 Q를 출력하였습니다.
따라서 Q함수는 상태 s와 행동 a에 대한 함수입니다. 즉 Q(s, a) 입니다. 그렇다면 Q함수는 어떤 형태일까요?
위의 그림에서, 플레이어가 '바위' 상태 일 때 할 수 있는 행동은 '가위', '바위', '보' 3가지 입니다. 플레이어도 마찬가지로 '가위', '바위', '보' 이므로 3x3인 9개가 나오겠네요. 따라서 Q함수는 아래와 같이 정의될 수 있습니다. 쉬운 이해를 위해 '바위' 상태의 Q값만 구현하였습니다.

이렇게 구현한 Q(s, a)함수를 다른 말로 Q table(Q 테이블) 이라고도 합니다.
3. Q함수 업데이트
플레이어가 '주먹'인 상태 일 때 다음 상태에서 인공지능이 이기기 위해 '가위'를 내야겠다 했었죠? 그랬더니 플레이어가 '보'를 내었으므로 인공지능이 이겼습니다.
인공지능이 '가위'를 낼 수 있었던 이유는 플레이어가 '주먹'인 상태에서 '가위'의 Q값이 가장 컷기 때문에 가위를 선택한 것이였습니다. 이겼으니 가위의 선택은 타당했고, 플레이어가 주먹일 때 인공지능 가위 행동의 Q값을 더 증가시키면 되겠군요.
즉, Q함수 업데이트는 다음 상태가 아닌 직전 상태를 업데이트 시키는 것입니다.

따라서 Q함수는 아래와 같이 바뀌겠군요.

보상값을 r이라고 할 때 이를 수식으로 표현하면 아래와 같습니다.
만약 플레이어가 보가 아닌 가위를 냈다면 비겼기 때문에 -1의 보상을 받았을 것이고, 그러면 플레이어가 '바위'일 때 인공지능이 '가위'에 해당하는 Q값은 -1 감소하여 0이 됩니다.
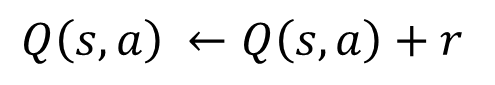
훈련 과정을 순서도 개념으로 표현해 보겠습니다.

사실 파이썬으로 하는게 (제 입장에선) 더 쉽지만, 저는 간단한 아두이노 게임기를 만들 에정이므로 다음시간에 아두이노 코드를 이용하여 표현해 보도록 하겠습니다.
'아두이노 + 인공지능' 카테고리의 다른 글
| 아두이노 강화학습(가위바위보AI) 3 - 아두이노 (0) | 2024.01.26 |
|---|---|
| 아두이노 강화학습(가위바위보AI) 1 - 강화학습이란? (0) | 2024.01.25 |

