강화학습을 이용하여 가위바위보 패턴을 분석하고 항상 이기는 AI를 아두이노로 만들어보고자 합니다.
그렇다면 강화학습이 무엇인지 알고 가야 겠지요?
이번 포스팅은
'심층 강화학습 인 액션'
심층 강화학습 인 액션 - 예스24 (yes24.com)
심층 강화학습 인 액션 - 예스24
프로젝트로 배우는 심층 강화학습의 이론과 실제!이 책 『심층 강화학습 인 액션』은 환경이 제공하는 직접적인 피드백에 기반해서 환경에 적응하고 자신을 개선해 나가는 에이전트의 구현 방
www.yes24.com
'모두를 위한 RL'강좌
Lecture 1: RL 수업소개 (Introduction) (youtube.com)
MATLAB 및 Simulink를 사용한 강화 학습 - MATLAB & Simulink (mathworks.com)
MATLAB 및 Simulink를 사용한 강화 학습
강화 학습의 기초를 학습하고 종래의 제어 설계와 비교해 볼 수 있습니다. eBook을 다운로드하여 MATLAB 및 Simulink에서 강화 학습을 시작해 보세요.
kr.mathworks.com
를 참고하였습니다.
1. 기계학습(머신러닝)의 종류
강화학습을 이해하기 위해선, 지도학습과 비지도학습의 차이를 알아야 합니다.

가. 지도 학습(supervised learning)
입력(feature)과 정답(label)을 알려주고, 주어진 입력을 이용하여 정답을 예측할 수 있는 모델을 훈련하는 것을 의미합니다.
아래와 같이 weight(무게), height(길이), num of legs(다리 갯수), communal living(공동 생활 여부), domesticatable(인간과 함께 생활하는가) 등 입력 (feature)을 토대로 훈련하여 rat(쥐), robin(울새), elephant(코끼리), rabbit(토끼), spider(거미) 등의 정답(label)을 맞추는 것입니다.
만약 신뢰할 수 있을 정도로 훈련한 모델이라면, 자료에 없는 새로운 동물의 특징을 입력하면, 훈련된 모델은 가장 확률이 높은 정답을 출력할 것입니다.
나. 비지도 학습(unsupervised learning)
비지도학습은 분류(Categorisation)되거나 정답(label)이 지정되지 않은 데이터셋에서 패턴 또는 숨겨진 구조를 찾는데 사용됩니다. 예를 들어 아래와 같이 동물 자료를 입력 하였을 때 유사한 특성 별로 그룹화 또는 군집화(clustering)할 수 있습니다. 이러한 그룹은 '다리의 개수'나 '인간과 함께 생활하는가' 등으로 분류할 수 있어 미처 알지 못했던 새로운 특성을 찾는데 사용되기도 합니다.
다. 강화학습(reinforcement learning)
강화학습은 위 개념과 전혀 다릅니다. 학습자(인공지능)은 어떤 행동을 취하라는 지시를 직접 받지 않으며 행동을 직접 취하면서 가장 많은 보상을 낳는 행동이 무엇인지 알아냅니다. 강화학습은 보상을 극대화하기 위해 어떤 행동을 해야 할지, 즉 최적의 결과를 낳을 최적의 행동을 찾는 것이 목표입니다.
여러분은 운동, 공부, 게임 등 재미있어서 빠져들어가며 한 적이 있을 것입니다. 재미가 없다면 하지 않았을 것이고 재미가 있다면 재미 자체가 보상이 되어 더욱 몰집하게 해주는 원동력이 되었을 것입니다.
이것을 일종의 강화라고 볼수 있는데요, 강화란, 좋은 보상을 받을 수 있는 행동의 재현을 높이는 것을 뜻합니다.
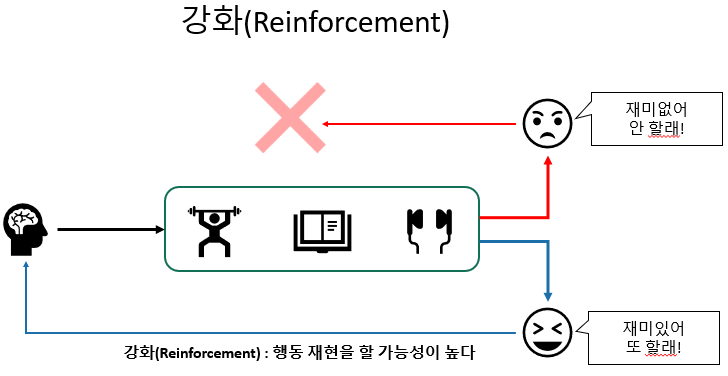
강화를 이용한 것이 강화학습입니다. 강화학습이란 현재의 상태를 인식하고, 선택 가능한 행동들 중 최대 보상을 받을 수 있는 판단 또는 행동을 선택하도록 학습하는 것을 뜻합니다.
스키너의 상자는 매우 유명하죠. Respopse lever를 누르면 Food dispenser에서 먹이가 나옵니다. 처음에 쥐는 우연히 레버를 누르게 됩니다. 먹이가 나온 것을 확인하고 먹이를 먹은 쥐에게 좋은 보상이 됩니다.
'먹이를 먹고 싶으면 레버를 누른다' 가 학습이 되었다고 볼 수 있습니다.
2. 맛집찾기로 본 강화학습의 원리
강화학습의 원리를 쉽게 이해하기 위해, 맛집 찾기로 설명해 보겠습니다.
지도나 스마트폰도 없이 여행지에 가서 맛집을 찾아본다고 가정합시다. 이 사람은 직접 찾아가서 맛을 봐야 맛집인지 아닌지 구별 가능할 것입니다.
아래와 같이 세 군데를 방문한 후 자신만의 맛집 지도를 만들었습니다. 맛 없으면 -5점, 맛있으면 +5점을 주었습니다.

이제 친구와 맛집을 찾아간다고 생각해 봅시다.
그렇다면 다음과 같은 가게 앞에서 친구가 "오른쪽 맛집 어때?"라고 물을 때 "그 쪽 집은 별로야" 라고 말할 수 있습니다. 즉 길에 대해서도 점수를 매길 수 있습니다(길점수). 오른쪽 집은 맛이 없으므로 오른쪽 방향을 -5점 부여할 수 있습니다.
친구에게 "아래쪽으로 가면 맛집이 있어" 이렇게 이야기하겠죠.
그러면 아래쪽으로는 좋은 점수를 매길 수 있는데 맛집에는 아직 도달하지 못했으므로 4.9점을 주면 좋겠지요.
결론은, 점수가 큰 방향으로 이동한다면 맛집을 찾아갈 수 있을 것입니다.

3. Q learning
이런식으로 계속 돌아다니면서 길점수를 매깁니다. 어느정도 돌아다닌 후 길 점수가 큰 방향으로만 가면 맛집에 도달할 수 있을 것입니다. 이제부터 이 점수를 '보상(reward)'라고 하겠습니다. 여기서 문제! 그렇다면 길 점수는 보상과 어떤 연관이 있는 것일까요?
길 점수라는 것은 해당 방향으로 움직였을 때 받을 '보상의 기대값' 즉, 보상의 '가치(value)' 입니다.
첫 번재 위치에서 오른쪽으로 움직였을 때 4.5의 보상을 얻고, 아래로 움직였을 때 0의 보상을 얻습니다. 즉 가치값은 어떤 함수(function) 형태입니다. 이러한 함수를 일반적으로 Q 함수(Q function)이라고 하고 위에서 언급한 4.5, 0의 가치값을 Q 가치(Q value)라고 합니다.

어떤 문제에 대해 Q함수를 구하고, Q함수가 최대가 되는 행동을 취한다면 성공적인 강화학습을 이룰 수 있을 것입니다. 이러한 강화학습을 Q learning 이라고 합니다.
4. 가위바위보 문제
자, 이제 우리의 목표인 가위바위보 AI를 구상해 볼 차례입니다.
당신의 단순한 패턴(가위→바위 →보 →가위 →바위 →보... 또는 보 → 가위 → 보 → 가위 ... 또는 바위 → 바위 → 바위...)
을 학습하여 당신을 항상 이기는 게임을 만들어 보고자 합니다. 그렇다면 인공지능은 사용자가 다음에 무엇을 낼지 예측할 수 있어야 합니다.
Q learning을 이용할 건데요, Q함수를 어떻게 정의하고, 어떻게 훈련해야 하는지는 다음 포스트에서 말씀드리도록 하겠습니다.
'아두이노 + 인공지능' 카테고리의 다른 글
| 아두이노 강화학습(가위바위보AI) 3 - 아두이노 (0) | 2024.01.26 |
|---|---|
| 아두이노 강화학습(가위바위보AI) 2 - Q learning (0) | 2024.01.26 |

