
유전 알고리즘 3.유전 알고리즘으로 이미지 훈련하기
이전 시간에는 적합도의 개념을 이용하여 3개의 숫자들의 합이 20이 되게 훈련하였다. 이번에는 유전 알고리즘을 이용하여 이미지를 원하는 대로 만들어 보자!
1. 특정 이미지가 만들어지게 하기
카드의 숫자를 유전정보라고 할 때 유전 객체를 [3, 5, 7] 이런식으로 표현했다. 이 [3, 5, 7]을 1차원 배열이라고 한다. 일반적으로 컴퓨터에서 그려지는 이미지는 2차원 배열인데 2차원 배열을 이용하여 특정 이미지가 그려지도록 훈련할 수 있다.

3차원 배열도 있다. 여러분이 생각하는 가로, 세로, 높이로 생각해도 좋다.
2. 생성, 자연선택, 돌연변이 코드 구현하기
1) 목표 설정
import numpy as np # 넘파이 모듈 임포트
np.random.seed(220329) # 랜덤 시드 생성
# 학습 목표(target) 설정
target = np.array([[1, 1, 1, 1],
[1, 0, 0, 1],
[1, 0, 0, 1],
[1, 1, 1, 1]])
print(target.shape) # (4, 4)이번 유전알고리즘의 목표는 target이 되도록 객체를 만드는 것이다.
2) 유전 객체 생성
def create_genome():
return np.random.choice((0, 1), (4, 4))
print(create_genome()) # shape은 (4, 4)2 – np.random.choice((0, 1), (4, 4)) : 0과 1로 이루어진 행렬을 4행 4열로 랜덤하게 만든다 라는 뜻이다.
3) 1세대 유전자 객체 4개 생성
#1세대 유전자 객체 4개 생성
gen_list = create_genome()
for i in range(3):
value = create_genome()
gen_list = np.vstack((gen_list, value)) #(16, 4), 2차원 배열을 그냥 이어붙임
print(gen_list) # (4, 4, 4) # 2차원 배열을 3차원 배열로 변환
gen_list = np.reshape(gen_list, (-1, 4, 4))
print(gen_list)코드설명
2 – gen_list : (4, 4)의 0과 1로 이루어진 객체를 하나 생성한다.
3 – 3번 반복한다. (왜 이렇게 밖에서 한번 생성하냐면 vstack은 shape이 다르면 결합X)
4 – gen_list와 결합할 새로운 객체 value를 생성
5 – vstack을 이용하여 객체를 쌓는다. stack은 쌓는다 라는 뜻이고 v는 vertical(세로)의 줄임말이다. i = 0 일
gen_list→(4, 4), value→(4, 4) 이므로 세로로 쌓게 되면 (8, 4)가 된다. 이를 3번 반복하면 (16, 4)가 된다.
4) 적합도 정의해 보기
적합도를 아래와 같이 정의해 보자.
# 적합도 계산해 보기
appro = np.abs(target-gen_list[0])
print(appro)
appro = np.sum(appro)
print(appro)
print(np.sum(np.abs(target-target)))코드설명
2 – 목표 객체와 gen_list의 첫 번째 객체(gen_list[0])의 차이를 절대값으로 씌운다.
4 – 각 요소들 끼리 합한다. → 배열이 아닌 숫자가 출력
7 – target에 대한 적합도를 확인해 본다.
5) 객체 4개에 대한 적합도 계산
# 적합도 계산
def Appropriate(list_gen):
appro_list = np.array([])
for gen in list_gen:
appro = np.array([np.sum(np.abs(target-gen))])
appro_list = np.concatenate([appro_list, appro], axis=0)
return appro_list
print(Appropriate(gen_list))이전과 같은 원리로 적합도를 계산 한다.
6) 객체 4개에 대한 적합도 계산
# 개체 중 적합도가 가장 작은 2개의 객체 선택하기
def Select_appropriate(list_gen):
list_appro = Appropriate(list_gen) # 적합도 배열
argsort = list_appro.argsort() # 적합도 배열 인덱스 오름차순 정렬
select_one = list_gen[argsort[0]] # 적합도가 가장 작은 객체
select_two = list_gen[argsort[1]] # 적합도가 두 번째로 작은 객체
two_genlist = np.vstack((select_one, select_two)) # 적합도 객체 쌓기 (8, 4)
two_genlist = np.reshape(two_genlist, (-1, 4, 4)) # shape 재정의 (2, 4, 4)
return two_genlist
print("유전 객체 4개")
print(gen_list)
print("각 적합도 계산")
print(Appropriate(gen_list))
genlist_two_origin = Select_appropriate(gen_list)
print("적합도가 가장 작은 2개 선택")
print(genlist_two_origin)
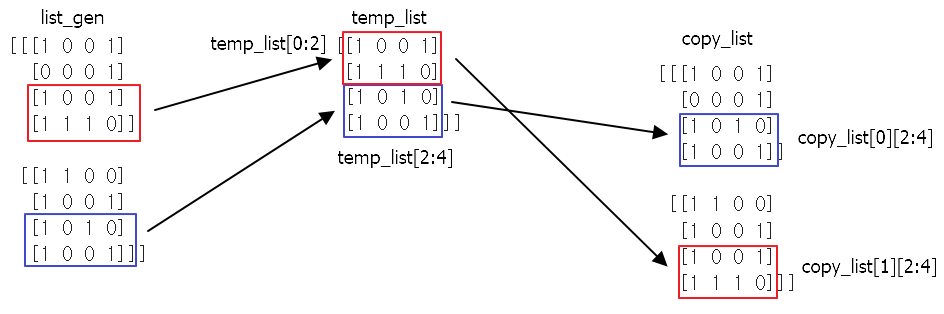
7) 감수 분열을 이용한 교차 구현
감수 분열을 하면 행 1-2(인덱스 0, 1) , 행 3-4(인덱스 2, 3)로 분열된다. 서로 교차할 물질은 행 3-4번 끼리 서로 교체함.
# 유전자 객체 2개 교차, 밑의 2개 행을 서로 교차한다.
def intersect_genorm(list_gen):
temp_list = np.vstack((list_gen[0][2:4], list_gen[1][2:4]))
copy_list = genlist_two_origin.copy()
copy_list[0][2:4] = temp_list[2:4]
copy_list[1][2:4] = temp_list[0:2]
return copy_list
print("두번째 자리 교차 전")
print(genlist_two_origin)
intersect_gen = intersect_genorm(genlist_two_origin) # 두 번째 자리 교차
print("두번째 자리 교차 후")
print(intersect_gen)코드설명
3 – temp_list : 감수 분열된 객체가 vstack으로 쌓임 (2, 2) , (2, 2) → vstack → (4, 4)
temp_list 1~2행 : select_one의 3~4행, / temp_list 3~4행 : select_two의 3~4행
4 – 부모 객체를 복사하여 자식 개체로 사용하자.
5 – copy_list[0][2:4]은 원래 select_one의 3~4행임. 이를 temp_list의 3~4행 즉 selct_two의 3~4 행으로 교환
5 – copy_list[1][2:4]은 원래 select_two의 3~4행임. 이를 temp_list의 1~2행 즉 selct_one의 3~4 행으로 교환
8) 확률 구현하기
파이썬에서는 확률을 어떻게 표현할까?
# 확률 구현, 0만 뜨면 여러번 실행해 보자
prob = 0.3
for i in range(10):
event = np.random.choice((0, 1), p=[1-prob, prob])
print(event)코드설명
prob = 0.3으로 정의하면
4- (0, 1), p=[1-prob, prob]에서 코드를 실행했을 때 0을 선택할 확률은 1-0.3 = 0.7, 1을 선택할 확률은 0.3 이다.
p는 각 수를 선택할 확률을 의미하며 p를 구성하는 배열의 합은 1이 되어야 한다.
9) 돌연변이 구현하기
조금 더 복잡한 돌연변이를 구현해 보자.
# 확률요소와 조금 더 복잡한 돌연변이가 가능하다.
def Mutation(list_gen, prob=0.5):
event = np.random.choice((0, 1), p=[1-prob, prob])
if event == True:
mutant_list = np.random.choice((0, 1), (4, 4))
copy_list = genlist_two_origin.copy()
high_low = np.random.choice((0, 1), p=[0.5, 0.5])
if high_low == True:
copy_list[0][0:2] = mutant_list[0:2]
copy_list[1][0:2] = mutant_list[2:4]
else:
copy_list[0][2:4] = mutant_list[0:2]
copy_list[1][2:4] = mutant_list[2:4]
return copy_list
else:
return list_gen
print('before Mutation : 정상적인 교차로 인한 자식 생성')
print(intersect_gen)
print('after Mutaion : 자식 생성 중 돌연변이 발생')
print(Mutation(genlist_two_origin))
코드설명
3 – 1이 선택될 때 event = 1
4 – event = 1일 때 조건이 성립되어 if문으로 진입
5 – mutant_list = 돌연변이 리스트 0과 1로 이루어진 (4, 4) 생성
7 – 돌연변이 다양성을 위해 위의 2행을 변화시킬지, 아래 2행을 변화시킬지 정하는 랜덤 함수. hight_low = 1이면 위 2행을 변화시키고, high_low = 0 이면 아래 2행을 변화시킨다. 위와 아래는 동전 뒤집기 확률로 0.5씩 각각 고정해두었다.

10) 객체 2개 + 객체 2개 구현하기
파이썬에서는 확률을 어떻게 표현할까?
# 4개의 객체 중 적합도가 가장 작은 유전 객체 2개 + 유전 객체 2개 교차 구현한 것 합치기
def combine_genome(list_1, list_2):
return np.concatenate((list_1, list_2))
combine_gen = combine_genome(genlist_two_origin, intersect_gen)
print("1세대 두번째 자리 교차 전 + 교차 후")
print(combine_gen)
11) 반복 훈련을 위한 객체 4개 생성하기
# 1세대 유전체 객체 4개 생성
gen_list = create_genome()
for i in range(3):
value = create_genome()
gen_list = np.vstack((gen_list, value))
genlist_four = np.reshape(gen_list, (-1, 4, 4))
genlist_two_origin= Select_appropriate(genlist_four)
print('genlist_two_origin')
print(genlist_two_origin)
12) (최종) 반복 훈련하기
epochs = 3000
for epoch in range(epochs):
# 부모 세대가지 합쳐 4개 중 적합도가 가장 큰 2개 선택
genlist_two= Select_appropriate(genlist_four)
# 유전자 교차(자손 번식)
intersect_gen = intersect_genorm(genlist_two)
# 돌연변이 진입, 조건이 해당하면 돌연변이 발생
intersect_gen = Mutation(intersect_gen, prob=0.2)
# 부모세대와 자식세대를 합쳐 4개로 만듦
genlist_four = combine_genome(genlist_two, intersect_gen)
genlist_last_two= Select_appropriate(genlist_four)
print('genlist_last_two')
print(genlist_last_two)

원하는 모양에 거의 가깝게 출력된 것을 알 수 있다.